In the tenth installment of Data Replicada, we report our attempt to replicate a recently published Journal of Consumer Research (JMR) article entitled, “Goal Conflict Encourages Work and Discourages Leisure” (.htm).
The article’s two key hypotheses are right there in the title: People who are faced with a goal conflict are (1) more likely to spend time on work and (2) less likely to spend time on leisure. This is because “goal conflict increases reliance on salient justifications” and “work tends to be easier to justify and leisure harder to justify” (Abstract).
This JCR paper contains seven studies, and three of those used MTurk participants. We chose to replicate Study 1a (N = 210) because it represented a simple test of both of the authors’ hypotheses. In this study, participants first listed two goals that they were currently pursuing (e.g., “lose weight” and “save money”; or, “grow a bigger garden” and “get a dog”). They were then randomly assigned to write about ways in which those goals either do or do not conflict. Following that task, participants were introduced to an ostensibly unrelated book-browsing task that was framed as either work or leisure, and the researchers recorded how much time the participants spent on this task. They found that participants in the goal conflict condition spent more time on the book-browsing task when it was framed as work and less time on the book-browsing task when it was framed as leisure.
We contacted the authors to request the materials needed to conduct a replication. They were forthcoming, thorough, and polite. They immediately shared the original Qualtrics file that they used to conduct that study, and we used it to conduct our replication. They also promptly answered a few follow-up questions, and provided us with data that allowed us to better compare the results of our replications and their original study. We are very grateful to the authors for their help and professionalism.
The Replications
We ran two identical replications. The first was run on MTurk using the same criteria the original authors specified. The second was run on MTurk using a new(ish) feature that screens for only high-quality “CloudResearch Approved Participants” [1].
In the pre-registered replications [2], we used the same survey as in the original study, and therefore the same instructions, procedures, stimuli, and questions. These studies did not deviate from the original study in any discernible way, except that our consent form was necessarily different, and our exclusion rules were slightly different [3]. After exclusions, we wound up with 1,008 participants in Replication 1 and 1,127 participants in Replication 2 (~5 times the original sample size). You can (easily!) access all of our pre-registrations, surveys, materials, data, and code on ResearchBox (.htm).
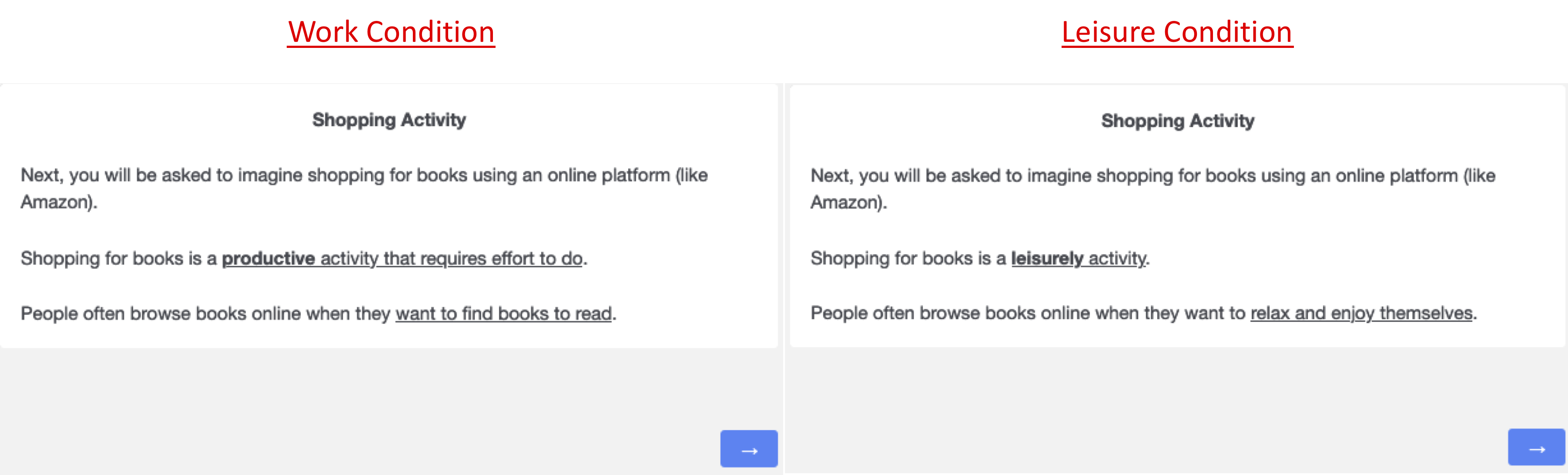
In each study, participants were first asked to “list two of your goals.” Then, on the next page, they were randomly assigned to either “describe a time when you DID NOT FEEL conflict between these goals” (the No-Conflict condition) or to “describe a time when you felt conflict between these goals” (the Conflict condition).
Participants then moved on to a separate book-browsing task, which was either described as work or leisure, as shown here:
Participants then engaged in the book-browsing task itself. Here is how it looked:
![]()
If participants clicked the box next to any of the books, the book’s description would appear below this array. They could spend as little or as much time on the task before proceeding, up to an undisclosed limit of 300 seconds, at which point the survey auto-advanced to the next screen.
The primary dependent measure was the time participants spent on this screen.
After this task, participants completed some manipulation check measures, an attention check, and some demographic questions.
Results
Before presenting the results, it is worth discussing our analysis plan. The original authors offered and tested two independent hypotheses, and so we pre-registered to conduct separate tests of those hypotheses. Specifically, we examined whether participants who did vs. did not write about goal conflict (1) spent more time on the book-browsing task when it was framed as work, and (2) spent less time on the book-browsing task when it was framed as leisure.
As in the original article, our critical dependent measure was the natural log of seconds spent on the book browsing task [4]. Here are the original vs. replication results:
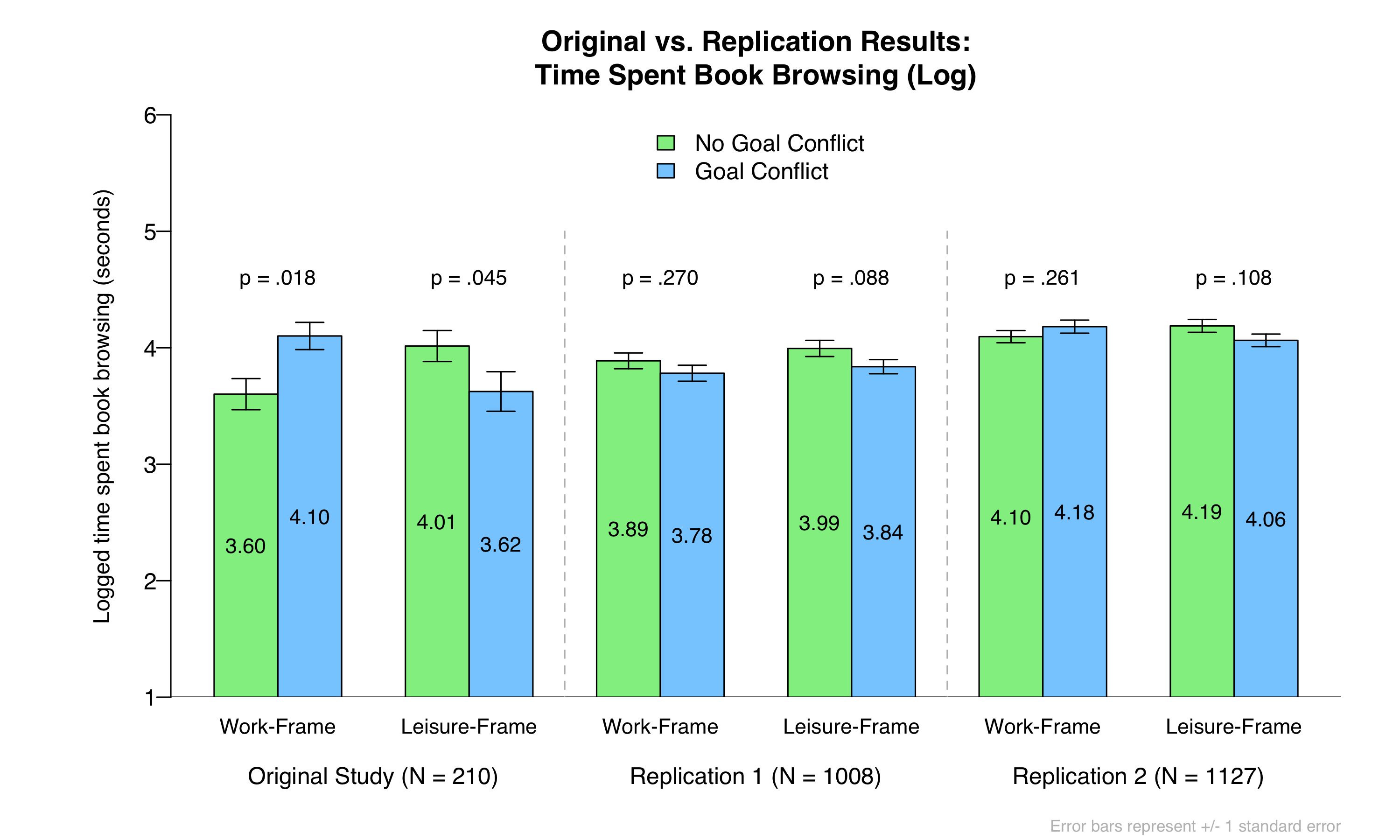
Let’s consider each of the two independent hypotheses.
First, did writing about goal conflict increase the time spent on the book-browsing task when it was framed as work? Although the original authors reported fairly strong support for this hypothesis (d = .58), we found no evidence for it, despite having about five times more observations than in the original study. If this effect is real, it is very small, as we observed a small negative effect in Replication 1 (d = -.098) and a similarly sized positive effect in Replication 2 (d = .096). With only ~53 per cell, we estimate that the original authors had only 0.7% power to detect the effect size we observed in Replication 1 and only 7% power to detect the effect size we observed in Replication 2 [5]. You’d need ~1,700 per cell to have 80% power to detect an effect of the size that we observed in Replication 2 (i.e., d = .096).
Second, did writing about goal conflict decrease the time spent on the book-browsing task when it was framed as leisure? Although this effect is not significant in either of our replications, we do find directional and marginally (or close-to-marginally) significant support for it in both. Nevertheless, the effect sizes we observed (ds = -.13 and -.15) are much smaller than what was reported in the original (d = -.34), again indicating that the original study had only 10-12% power to detect such an effect. You’d need ~800 per cell to have 80% power to detect effects of that size (i.e., ds of about -.15).
On balance, then, these replications were not successful. If the effects exist, they could not have been detected in the original study [6].
What About Data Quality?
Although no one can ever definitively rule out that a replication failed because of either lower data quality or the mere passage of time, it is worth noting that our descriptive statistics and data quality seem comparable to the original study.
First, we found that participants in our first replication – which sampled from the same population as the original study – averaged almost the same amount of time on the book-browsing task (M = 71.2 sec, SD = 69.7) as did participants in the original study (M = 73.2 sec, SD = 67.9) [7]. This suggests that our MTurk participants were approaching the task in a way that was similar to how MTurkers in the original study approached it [8].
Second, after the book browsing task, participants answered questions designed to serve as a check on the effectiveness of the goal conflict manipulation. Just as in the original study, we found a highly significant effect of goal conflict on this measure (ps < 10-10).
Conclusion
In sum, we did not find significant or consistent evidence that writing about a goal conflict increases time spent on a book browsing task framed as work. We did find marginally significant evidence that writing about a goal conflict decreases time spent on a book browsing task framed as leisure, but the effect, if it exists, is so small that the original study could not have reliably detected it.
![]()
Author Feedback
When we reached out to the authors for comment, they had this to say:
“We were encouraged to see the overall pattern of results from the original study emerge in the second, higher-quality replication sample, as well as in the leisure frame condition of the first sample (although with smaller effect sizes).
Further, as footnoted in Data Colada’s post, in the second replication, the interaction predicted in the paper is also significant. Although we appreciate Data Colada’s rationale for interpreting our time spent hypothesis as two simple effects, not all experiments in the paper test such separate time spent on work versus leisure (i.e., consider relative time allocated to work versus leisure instead). We acknowledge that the wording of our paper title and time spent prediction resulted in some (unintended) ambiguity regarding germane tests of our theory.
We also note that the context in which the replications were run—December 2020, at the height of the COVID-19 pandemic in the United States—may be relevant. Indeed, reviewing the data, the pandemic appears regularly in participant responses, with some even referencing it to counterargue the goal conflict manipulation. While we were glad the goal conflict manipulation check worked, the ongoing upheaval in participants’ daily lives and personal goals may have nevertheless impacted how they were influenced by the prompt. Moreover, the pandemic has created widespread change in how people both engage in and experience work and leisure (e.g., Giurge, Whillans, and Yemiscigil 2021; Kniffin et al. 2021; Lashua, Johnson, and Parry 2021; Sugar 2020, .html). Although the replication (consistent with the original study) does not include a work-leisure manipulation check, we surmise that sensitivity to the work-leisure manipulation (framing time spent on the same online book browsing task as a “leisurely” vs. “productive” activity) may be influenced by this broader context.
Overall, we appreciate the Data Colada team’s interest in this research and support the replication effort. We hope this may increase interest in advancing understanding of goal conflict and its effect on time use.”
Footnotes.
- Specifically, in the first replication, we used MTurkers with at least a 96% approval rating. In the second replication, we used only “CloudResearch Approved Participants” with at least a 96% approval rating. As in the original, the survey software prevented mobile phone users from taking the survey.[↩]
- As always, we intended to pre-register our replications. However – and this is embarrassing – as we were preparing to put the files on Research Box after writing a draft of this post, we realized that we somehow forgot to submit our pre-registration answers, which we typed up in a Word document, on AsPredicted.org for the first replication. So we didn’t actually officially pre-register this study. Importantly, we did not know this until we completed all of our analyses, and, except for a minor deviation (reported below) that has zero consequences, we perfectly followed what we had decided to pre-register. We have uploaded the Word document containing this pre-registration to ResearchBox. If you look at its properties, you’ll see that we have not modified this document since December 1, 2020, two days before running Replication 1. So for all intents and purposes, this study was effectively pre-registered, despite our blunder. So we will refer to it as such.[↩]
- In keeping with the original authors, we excluded participants who failed an attention check or who spent more than 30 minutes on the survey. In addition, for quality control, we pre-registered to exclude all observations associated with duplicate MTurk IDs or IP Addresses, and to exclude those whose actual MTurk IDs were different from their reported IDs.[↩]
- As mentioned above, the time spent on the book browsing task was capped at 300 seconds by the book-browsing software. Nevertheless, a few participants spent a couple seconds more time than that, and one participant in our first replication somehow managed to spend more than 400 seconds on the task. (This participant also reported having some technical difficulties with the survey.) As a result, we winsorized all times exceeding 300 seconds down to 300 seconds prior to conducting our analyses. We did not pre-register this in our first replication, as we did not foresee the issue, but we did so in our second. The effects of this analytic decision are trivial. For example, if we do not winsorize in this way in Replication 1, the work-frame p-value becomes .264 instead of .270, and the leisure-frame p-value remains at .088.[↩]
- These power calculations reflect the probability of observing a significant effect that is the *same direction* as in the original study, using a two-sided test. This represents a departure from how we computed power in past Data Replicadas, but we think it is superior, both because we obviously care about the likelihood of finding an effect that is directionally consistent with the original study, and because this approach allows us to compute implied power even when the effect observed in the replication is in the opposite direction of the original. By this approach, the likelihood of finding a significant effect in the original direction if true d = 0 would be .05/2 = .025. The likelihood of finding a significant effect in the original direction if the true effect is in the *opposite* direction would be less than .025.[↩]
- As noted, we pre-registered to separately analyze the effect of goal conflict on time spent on the work-framed task and on time spent on the leisure-framed task. This is appropriate whenever the key prediction is a crossover interaction, because the interaction itself may not fully support that hypothesis. For example, an interaction can be significant even if only one or neither of the hypothesized simple effects has statistically significant support. Nevertheless, readers may be curious about the goal conflict x work/leisure-frame interaction in these studies. This interaction was significant in Replication 2, b = 17.60, SE = 8.55, t(1,123) = 2.06, p = .040, and non-significant in Replication 1, b = 8.35, SE = 8.61, t(1,004) = 0.97, p = .333.[↩]
- The medians were also very similar: 52.4 in the original study vs. 53.6 in Replication 1.[↩]
- The CloudResearch Approved participants in Replication 2 spent longer (M = 87.2 seconds, SD = 72.5, Median = 66.7), which is consistent with what we have been finding in the last few Data Replicadas: These participants take greater care when completing surveys. As further evidence, more participants failed the attention check (and were thus excluded) in Replication 1 (13.2%) than in Replication 2 (3.6%).[↩]