Over the past 10 years or so, posting data, code, and materials for published papers has gone from eccentric to mundane. There are a few platforms that enable sharing research files, including ResearchBox.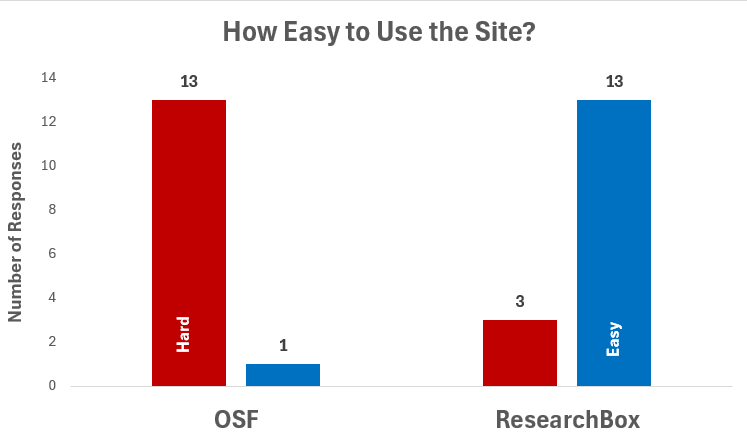
ResearchBox is hosted by the Wharton Credibility Lab, which I co-direct. We also host the pre-registration platform AsPredicted, and a new platform for results provenance we just launched, AsCollected. I will write about AsCollected in another blog post soon.
It’s not just me: ResearchBox is easier to use and more effective than the OSF
I find ResearchBox very easy, even pleasant to use, fast, and effective. But I was involved in designing ResearchBox so I can’t really judge. You may be unsurprised to learn that I also think my kids are remarkable, and the food I ate as a kid is some of the best in the world [1].
My situation, then, is that I have an intuition —ResearchBox is better— but don’t know if it is actually true for other people. It turns out that as a behavioral scientist I have just the right tool to figure out whether my intuitions are universally true: design a Qualtrics survey and give it to MTurkers. I took the OSF page (htm) of a JEP:G paper (htm) we had just read in journal club, downloaded all files, and created its twin repository on ResearchBox (htm).
They look like this:
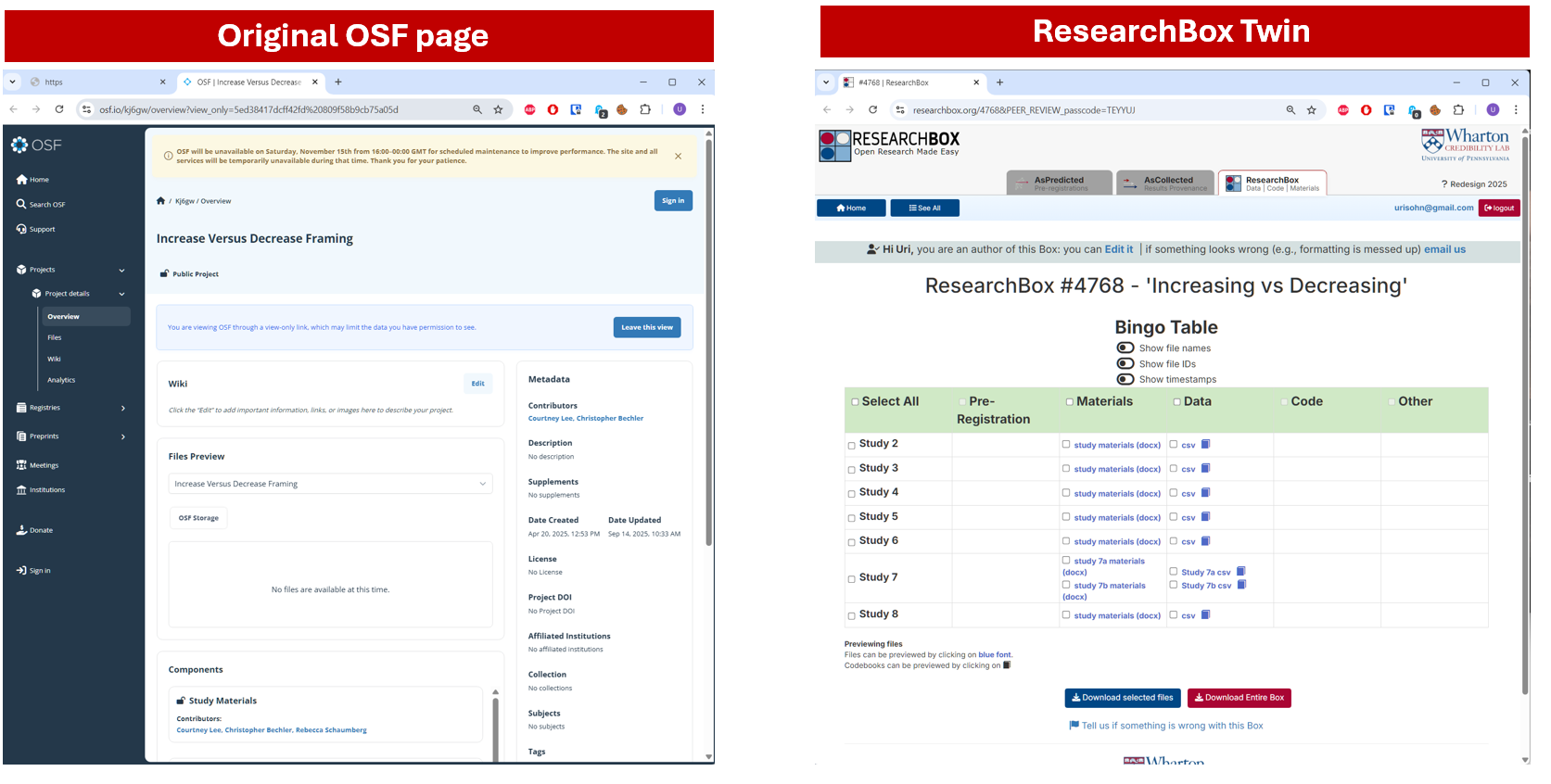
I then randomly assigned N=30 Cloudresearch participants to get the OSF or the ResearchBox link and asked them questions about the files. I ran a ridiculously small sample because I expected ridiculously large effects. The results supported my intuitions.
Survey Comparing Experience using OSF vs ResearchBox
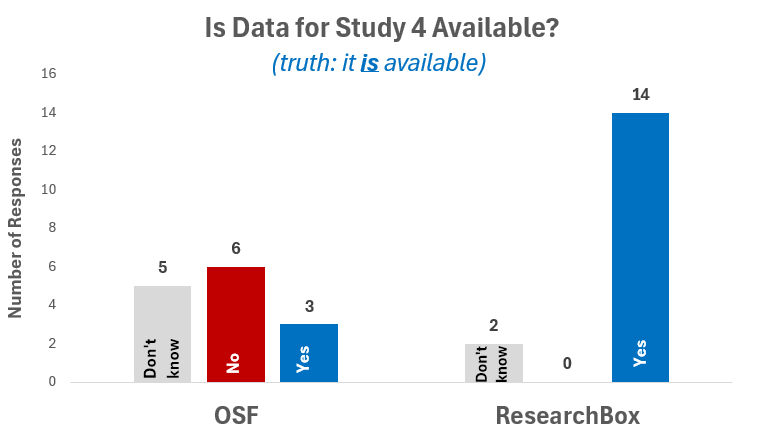
Question 1. Is the data for Study 4 available? See figure with results
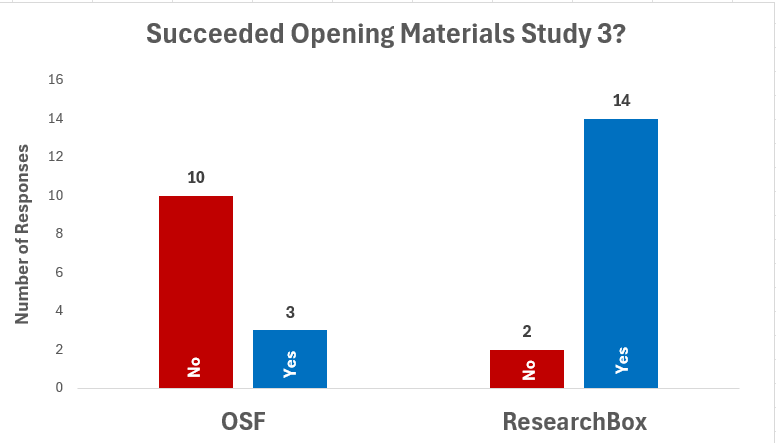
Question 2. Can you download the “Study Materials” for Study 3? See figure
Question 3. How easy to use is the website? See figure
Naturally, there are important limitations to this exercise, including that I only used one repository and that these differences may attenuate with experience. Maybe PhDs using the OSF for years are as fast navigating the site as MTurkers are navigating their first ResearchBox [2].
ResearchBox is more transparently permanent than before
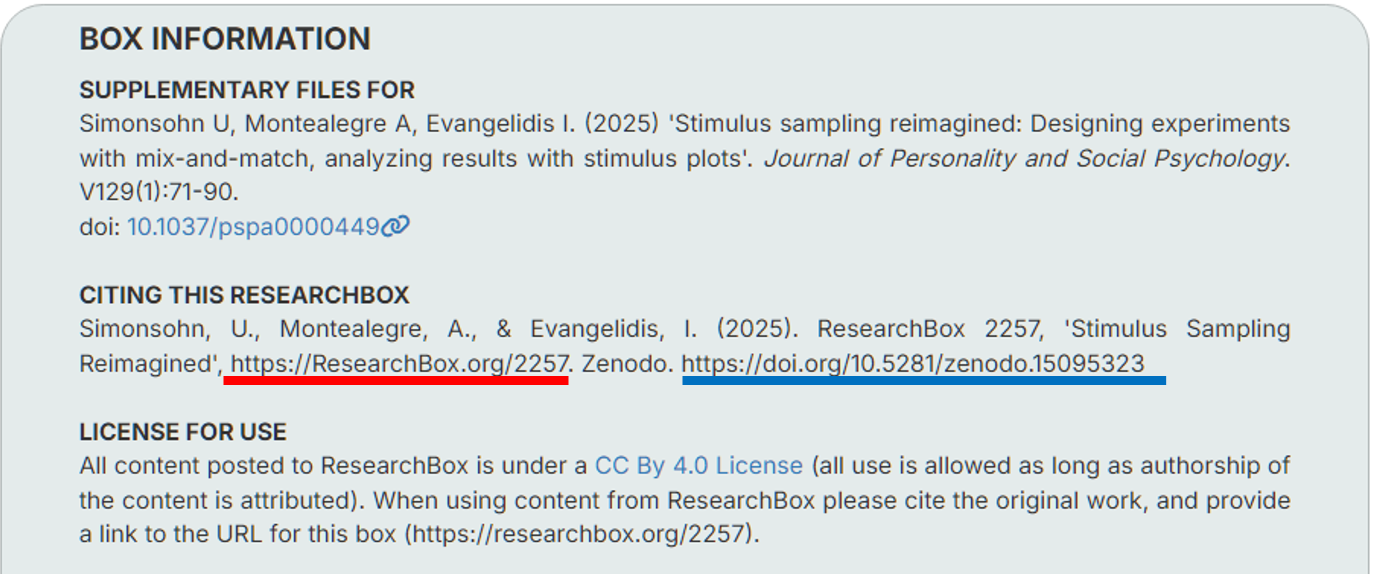
Every data repository needs to think about how files will remain available after the platform ceases to exist. Like the OSF, ResearchBox relies on the Web Archive (archive.org) for this purpose. When a box becomes public, a zip file with its entire contents is saved to a single archived folder containing every public ResearchBox (see that folder here).
In addition, ResearchBox now also backs up all public boxes to Zenodo, a European Union funded open science repository. Zenodo also generates DOIs. ResearchBox then generates the following recommended reference for each public box, it shows both the current URL (underlined in red) and the backup DOI for Zenodo (underlined in blue)
Codebook requirements took a chill pill
From the very beginning, every dataset on ResearchBox has had a codebook (you cannot post data without a codebook). While it generally makes sense to describe all variables in a traditional tabular format, sometimes there are too many variables and sometimes it makes more sense for authors to do their own thing describing the data (with free text). So we have relaxed the requirement that all variables be described.
Now authors can describe as few as 10 variables in a dataset, and can provide a free text codebook if they prefer. We still encourage people to describe all variables.
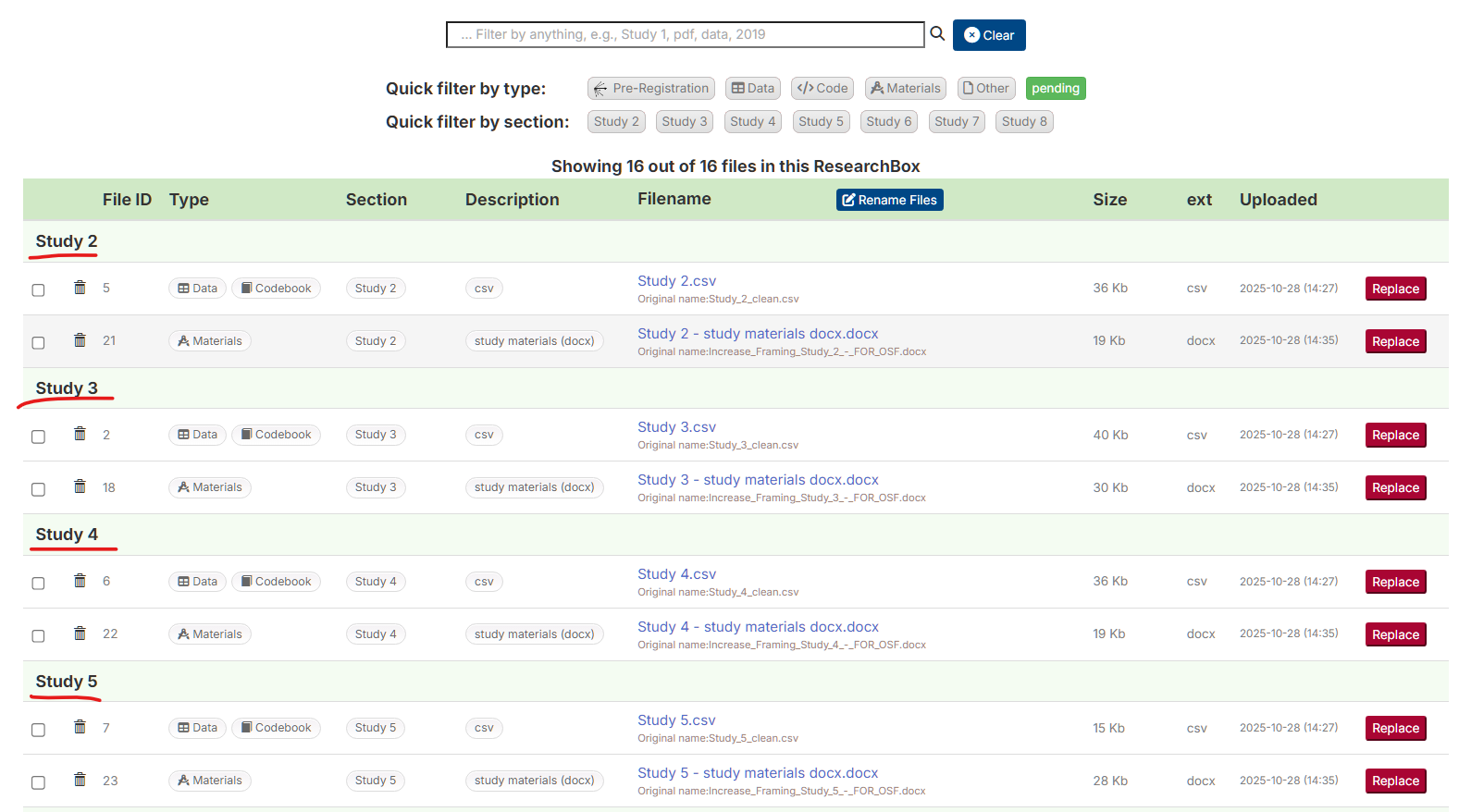
Upload Facelift
Among many updates to the page where authors upload and organize files, there are now automatic dividers to visually group of file, like folders. By default, files are sorted by section, and look like this:
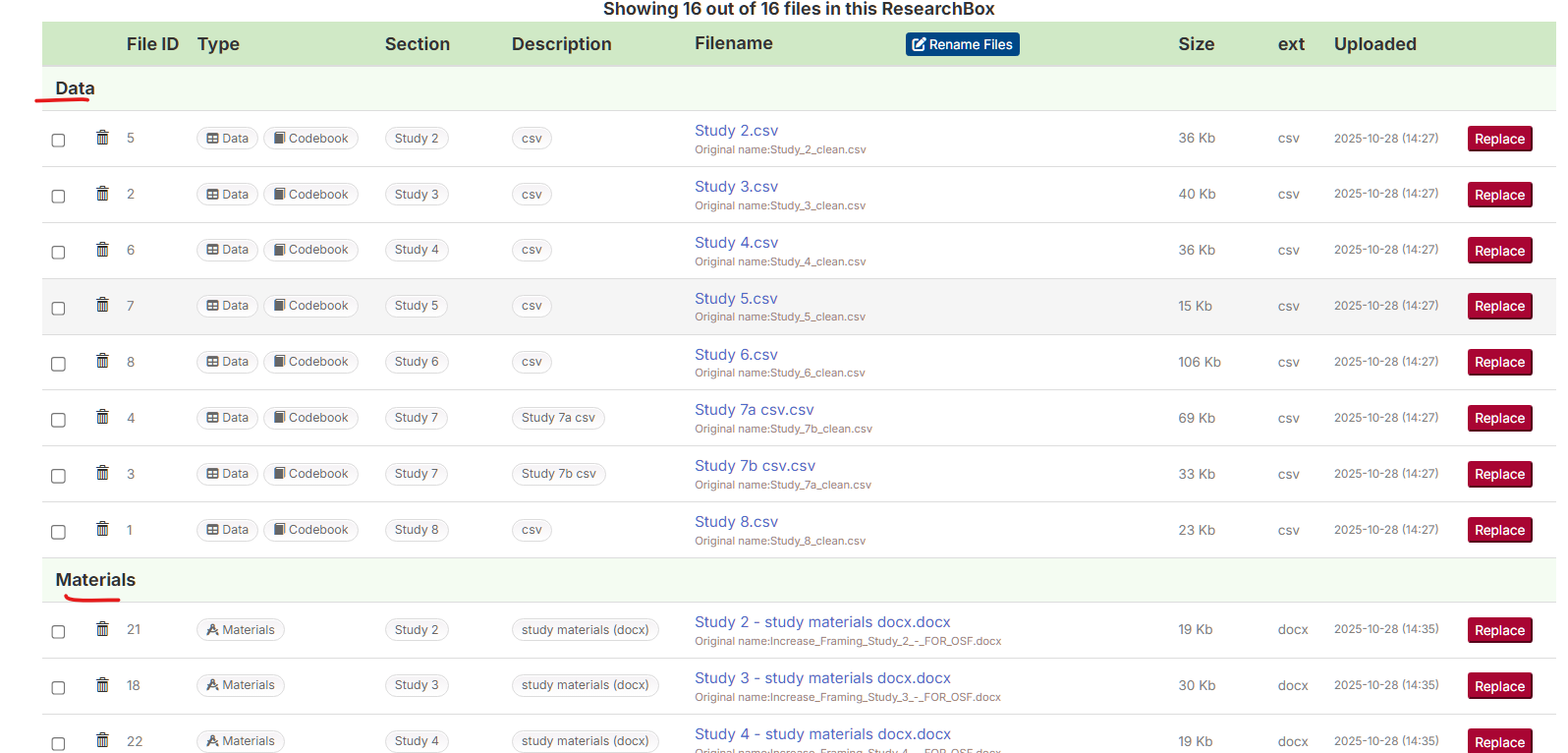
To group files by type, we just click that header and:
More integrated with AsPredicted
We have merged accounts with AsPredicted. Users logged in into one are logged in into the other. The platforms feel like a single website, navigating across them is seamless.

That middle-tab, “AsCollected”, is the topic of the next post.
Before I go
I emphasized here new things about ResearchBox, but some old things are valuable too.
The platform has many features no other open research platform has, including:
- The platform alerts authors if their posted code includes their name or email.
- The platform alerts authors if their posted data has participants identifying information (phone numbers, prolific IDs, IP addresses).
- Posted datasets can be searched by variable name or description
- e.g., I just checked and there are 160 variables described or named with
WTP(willingness-to-pay) and 24 with “Trump“
- e.g., I just checked and there are 160 variables described or named with
- Posted analysis scripts are searchable too.
- e.g., I just checked and there are 349 scripts using the
lmer() function for mixed models in R, and 150 scripts using thegroundhogpackage.
- e.g., I just checked and there are 349 scripts using the
- Every file can be instantaneously previewed by clicking on the name, even large datasets take about 2 seconds to be previewed.
![]()
Footnotes.
- I am referring of course to Pastel de Choclo and Porotos Granados

 [↩]
[↩] - My survey had a couple extra questions. I opened asking if there was data for Study 1, the right answer was “no”, I wanted it as a control in case everyone said “yes” in the OSF for Study 4. In ResearchBox 14 people say “no”, 2 said “don’t know”. In OSF 9 people said no, 1 said “yes”, 4 said they couldn’t tell. I also asked how fast the website felt, results were nearly identical to ease of use. I also timed how long it took people to provide their answers; the median successful OSF response about Study 4 took 126 seconds, in ResearchBox, 31 seconds[↩]