Mediation analysis is very common in behavioral science despite suffering from many invalidating shortcomings. While most of the shortcomings are intuitive [1], this post focuses on a counterintuitive one. It is one of those quirky statistical things that can be fun to think about, so it would merit a blog post even if it were inconsequential. But it is not inconsequential. On its own, the problem discussed here probably impacts the vast majority of published mediation analyses.
 This is hardly something I figured out – it's been known for 40+ years- but I have not seen the intuition for this problem fleshed out anywhere (checkout my reading list [2]). Maybe that’s why the problem has been largely ignored by researchers. It's hard to get worked up about something one does not understand.
This is hardly something I figured out – it's been known for 40+ years- but I have not seen the intuition for this problem fleshed out anywhere (checkout my reading list [2]). Maybe that’s why the problem has been largely ignored by researchers. It's hard to get worked up about something one does not understand.
Mediation analysis in a nutshell
In mediation analysis one asks by what channel did a randomly assigned manipulation work. For example, suppose that an experiment finds that randomly assigning Calculus 101 students to have quizzes every week (X) increased their final exam grade (Y). Mediation analysis is used to test whether this happened because quizzes led students to study more hours through the semester (M). Mediation is present if the estimated effect of X gets smaller when controlling for M (when c' < c in the regressions below).
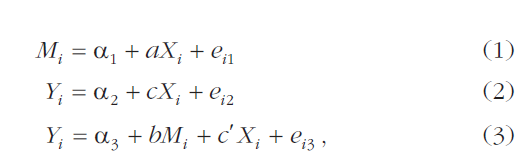
Stating the counterintuitive problem
The problem of interest to this post is that if M and Y are correlated outside of the experiment (i.e., independently of X), a very likely scenario, mediation is invalid.
[I edited this paragraph on 2022-10-16 to incorporate reader feedback]
Imagine that kids who love math do many things that can improve their grade (Y), including studying (M). Love of math correlates with M & Y. Boom. Mediation for the quiz experiment is now invalid.
Or, imagine that kids who care about grades do many things to get better grades (Y), including studying (M). Caring about grades correlates with M & Y. Boom. Mediation is invalid again.
In what sense is the 'boom' counterintuitive?
Given that X is randomly assigned, one might have expected that it is not biased by omitted variables like love of math or caring about grades. That's kind of why we run experiments in the first place.
That expectation does apply to equation (2) Y=α+cX
We can leave out all other variables that impact Y; ĉ is anyway unbiased.
But it does not apply to equation (3), Y=α+bM+c'X
Including M in the regression messes up the magic of random assignment: b̂ & ĉ' are generally biased.
Specifically, b̂ in (3) is biased because, while it picks up the causal effect (if any) of studying, it also picks up the confounded effect of all things that correlate with studying outside the experiment. If people who love math go to class more often, or read Calculus Weekly in the toilet, regression 3 will wrongly attribute to studying what's actually coming from all that toilet reading. Classic omitted variable bias.
It is tempting to believe that, thanks to random assignment, this bias does not spread to X. But it does spread. Specifically, ĉ' in (3) is biased downwards [3]. Given that mediation is c-c', this means we over-estimate mediation, or even, that we see lots of mediation where there isn't any.

Intuition builder Step 1: You would show the same bias
Let's leave regression aside for now. Imagine you are offered $1,000 if you correctly guess which of two college students, Siri vs Alexa, does better in a calculus exam. We will consider two scenarios (see illustration below).
In the first scenario, all you know is that Alexa's class was randomly assigned to have quizzes.
You figure that because of the quizzes, Alexa probably studied more, so you bet on her.
This is like Equation 2: predicting grades only with condition assignment.
Now let's consider Scenario 2. You learn that math loving students study more hours, and you learn that Alexa and Siri studied the same number of hours. Who would you bet on now? To answer that, think first about whether Siri or Alexa love math more.
Siri studied as much as Alexa did despite not having quizzes, why would she do that? She must love math more than Alexa does. OK. So, in this scenario Siri and Alexa are perfectly matched on preparation (28 hours), but Siri loves math more, so now you would bet Siri gets a better grade.
Notice what this means: for a given level of the mediator, hours studied, you are placing a negative impact on having been assigned quizzes. So while you do believe that quizzes help with grades, you use quizzes as a negative indicator of grades when you control for the mediator.
This happens because once you control for number of hours studied, quizzes cannot possibly signal more studying, instead, they signal lack of love for math.
Intuition Step 2: OLS does what you just did.
The mediator M in equation (3), Y=α+bM+c'X, includes studying that is free of confounds (caused by the quizzes manipulation), but also includes studying that is full of confounds (caused by kids loving math and caring about grades). Therefore, b̂ is an average of the clean and confounded effects of studying.
Say that the causal effect of studying each extra hour is a +1% grade increase, while the confounded effect is + 3%. Oversimplifying things a bit, let's say we'd get about b̂=2%.
This omitted variable bias in b̂, estimated at 2% instead of 1%, means that OLS systematically over-predicts the grades for kids who studied because of the quizzes. If a quiz-kid studies 5 extra hours, OLS expects +10% grade, but it only actually goes up +5%
On average, kids in the quiz condition have positive prediction error. OLS is all about minimizing error so will try to compensate and it has only one way to do that in Y=α+bM+c'X… …make c' smaller.
Loosely speaking, OLS will bias ĉ' downwards by the average error arising from using b̂=2% instead of b̂=1% as the effect of studying for quiz-takers.
So just like you did in Scenario 2 above, OLS says, "OK, if Alexa and Siri both studied 28 hours (i.e., controlling for M), but Alexa was in the Quizzes conditions (X=1), she will score lower than Siri in the test", and to do that, OLS makes ĉ' smaller or even negative, producing spurious mediation.
R Script
Here is an example with simulated data (R Code), where the examined mediator does not actually mediate any part of the effect, but it is estimated to mediate 100% of it.
Conclusions: a sober takeaway
In general, if we do mediation analysis, it means we expect X to lead M and Y to be correlated in our experiment. If we expect that, we should expect that other factors, confounds, cause M and Y to be correlated outside our experiment.
This post explains why such correlation invalidates mediation. In other words, this post explains why, in general, we should expect mediation to be invalid.
![]()
Footnotes.
- Examples of intuitive shortcomings of mediation: the mediator of interest to the authors correlates with other mediators that are not of interest and thus not included in the regression. If the excluded mediators correlate with the included one, a very likely scenariothe included mediator picks up spurious mediation from the other ones. This bias also affects virtually every published mediation analysis. In addition, non-linearities and measurement error can produce spurious mediation, and there may be reverse causality with the 'dependent variable' causing the change in the mediator.
[↩]
- My mediation reading list
(stuff I (re)read while preparing this post):- Bullock Green & Ha (2010 .pdf)) discusses in detail the intuitive and non-intuitive shortcomings with mediation analysis.
- Bullock & Green 2021 (.htm) propose an interesting new approach for assessing mediation which combines (1) running multiple manipulations that differ in the expected intensity of the mediator, (2) conducting instrumental variable estimation
- I learned from Bullock et al that, Judd & Kenny (1981 .pdf; p.607) already discuss the problem with r(M,Y)≠0. Disappointingly, they do not mention this huge problem with mediation in their home-run 1986 paper that put mediation in (everyone's) map. Imagine if they had…
- Julia Rohrer has a 2019 blogpost (.htm) discussing a special case of the problem of interest here, experiments where there is no effect of the manipulation on the dependent variable, but due to r(M,Y)≠0 outside the experiment, there is an estimated mediated effect.
- Imai et al (2010 .pdf) a technical paper that, among other things, proposes sensitivity analysis for mediation to examine the role of r(M,Y). Section 5 in their article (p.60) is the most relevant for the topic of interest to this post.
- MacKinnon & Pirlott (2015 .pdf) review multiple articles on the topic of confounding in mediation analysis.
- Rohrer et al (2021 .htm) Discuss many pitfalls with the PROCESS path models, including the r(M,Y)≠0 outside the experiment problem.
[↩]
- The sign of the bias in ĉ' is the sign of cor(M,Y) outside the experiment, it is thus theoretically possible for ĉ' to be biased upwards, under-estimate mediation, if for some odd reason, r(M,X)>0 in the experiment but r(M,X)<0 outside of it [↩]