A PNAS paper (.htm) proposed that people object “to experiments that compare two unobjectionable policies” (their title). In our own work (.htm), we arrive at the opposite conclusion: people “don’t dislike a corporate experiment more than they dislike its worst condition” (our title).
In a forthcoming PNAS letter, we identified a problem with the statistical analysis in the PNAS paper. Correcting the problem eliminates experiment aversion for the 7 scenarios that we tested (7 of the 9 scenarios in the paper). The strict 500 word limit by PNAS precluded us from writing about design concerns we had, especially with the remaining 2 scenarios. Here we discuss the stats and design issues.
The PNAS paper has several strengths that are worth remarking on: across a large number of individual studies, spanning 9 domains, using traditional participant populations and also healthcare providers, the authors investigated a topic that is of general importance, posting code, data, and materials (making our letter and this post possible). Moreover the issues we raise here also concerned the authors at least to some extent, but after considering those same issues, we end up with a different interpretation of their findings.
The Statistical Issue: Comparing Means to Mins
In each of the 7 studies we re-analyzed from the PNAS paper (all studies in their Table 1), three separate groups of people indicated the acceptability of Policy A (e.g., motivate teachers with vacation days), Policy B (e.g., motivate teachers with bonuses), or an experiment randomly assigning A or B. In the PNAS paper, the average acceptability of the experiment was lower than of either policy. This was interpreted as evidence of experiment aversion, but actually, it can easily arise in its absence.
To illustrate, imagine an experiment giving people a dessert with either dairy (A) or peanuts (B). If 30% of people are lactose intolerant and another 30% have peanut allergies, A and B are each objectionable to 30% of people. However, the experiment is objectionable to 60% of them. This is not because of an aversion to experimentation. Rather, some object to A, while others object to B.

So if, say, 5% of people object to a teacher bonus, e.g., because they think teachers' regular pay should increase, and 5% object to more vacation days, e.g., because they think teachers already have enough vacation days, then 10% may object to an experiment over either policy.
This is why in our paper (.htm) policies A and B were evaluated by the same people, and we compared the least acceptable policy for each participant to the acceptability of the experiment. In the desserts example, we would compare the share of people objecting to the experiment, to the 60% objecting to either A or B.
Fixing the statistical issue
In the PNAS studies, each participant rated only one policy, thus we cannot determine each participant’s worst policy. We approximated this necessary analysis by pairing observations from the A and B conditions, using the posted data (.xlsx). We analyzed each resulting pair as if coming from one participant, computing the worst policy for each pair, and then averaging across participants. Because two evaluations made by the same person are not independent, we didn’t form pairs drawing observations independently from A and B. Instead, we collected new data (.xlsx), estimated the within-person correlation to be r=.33, and used that number to calibrate our analyses of the PNAS data (see footnote for details [1] ).
We found that experiments were not actually rated below the average worst arm for each participant: overall M=3.48 and M=3.44 respectively.
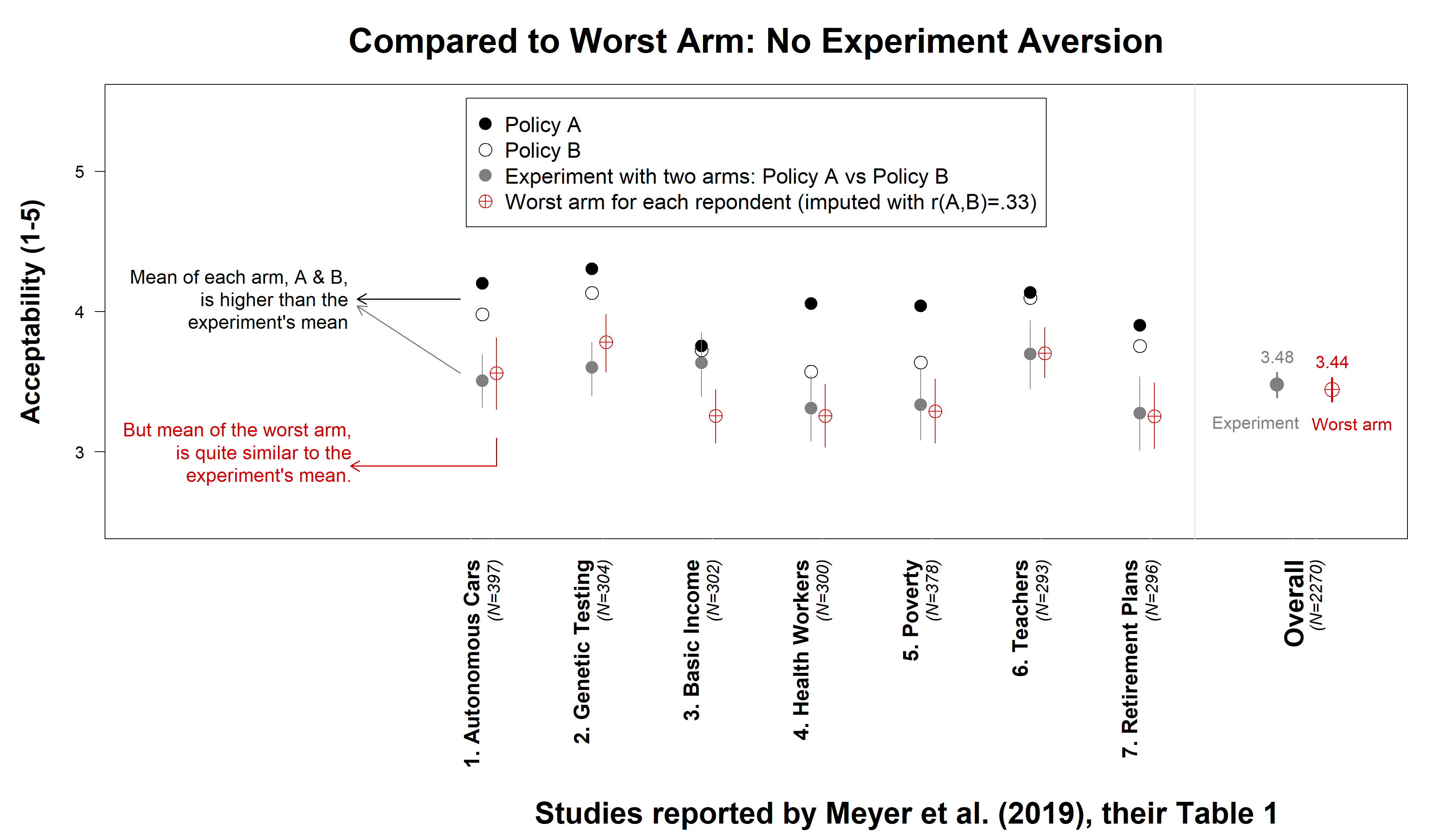 Fig. 1. No experiment aversion in PNAS data after fixing statistical issue. See footnote for details [2]. These results are not sensitive to the imputed correlation of r(A,B) = .33. With r = .5 the mean of the worst arm is M=3.51, with r = .2 it is M=3.40.
Fig. 1. No experiment aversion in PNAS data after fixing statistical issue. See footnote for details [2]. These results are not sensitive to the imputed correlation of r(A,B) = .33. With r = .5 the mean of the worst arm is M=3.51, with r = .2 it is M=3.40.
R Code to reproduce figure.
Next, the discussion that did not fit in the PNAS letter: the concerns we had with the designs of the 2 scenarios we did not statistically re-analyze. Some of these concerns apply to the previous 7 scenarios as well.
Scenario 8th of 9: Hospital director forgoes life-saving intervention
In the PNAS paper, Studies 1, 2 and 6a involved this scenario
A: Hospital director uses posters to remind doctors how to prevent deadly infections
B: Hospital director uses badges to remind doctors how to prevent deadly infections
A/B test: Hospital director runs an experiment, uses badges for some doctors, posters for others, and randomly assigns patients to doctors.
In this study, the A/B condition is -in our view- confounded because it not only introduces experimentation, but also describes a situation where a doctor forgoes a potentially life-changing action for no disclosed reason. This is not the case in the A and B conditions, where there is only one option available. Only in A/B, therefore, could the director’s decision cause deaths, and causing deaths for a trivial benefit (e.g., saving cost associated with printing posters) is objectionable. We believe a slightly modified study could have avoided such confound. For example, in the A and B conditions, the director could also identify both A and B as potential interventions and also only implement one of them for no disclosed reason.
Unnecessary deaths aside, is it a problem that only in the A/B condition people know that the two alternative policies are available? We share our view in this long footnote. In short: we don't think so. [3].
Scenario 9th of 9: Doctor Jones randomizes treatment to his patients
In the PNAS paper, Studies 4, 5 and 6b involved two very similar scenarios where multiple drugs for blood pressure are available and then:
A: “Doctor Jones wants to provide good treatment to his patients, he decides [to prescribe . . .] Drug A.”
B: “Doctor Jones wants to provide good treatment to his patients, he decides [to prescribe . . .] Drug B.”
A/B: “Doctor Jones thinks of two different ways to provide good treatment to his patients, so he decides to run an experiment […] Half of patients [get …] drug A, [… the other half…] drug B”
While all participants are told that Dr. Jones has multiple options available, only in A/B is Dr. Jones:
- Uncertain about how to provide care for his patients.
- Doing something potentially illegal (running a medical trial without oversight) [4].
Would a within-subject design version of the PNAS scenarios address our concerns?
We discussed with the PNAS authors whether a within-subject design would address our concerns. In a nuthsell:
First, a within-subject design would fix the statistical issue (but it can be fixed in other ways, see our analysis here of their between-subject design).
Second, a within-subject design would not eliminate what we perceive are confounds behind scenarios 8 & 9 (and some of the previous 7 scenarios).
In Sum
Our take of the existing evidence is that when people object to experiments, they don’t object to experimentation, instead they object either to the policies those experiments include, or—in scenario studies—to the additional information the experiment’s description reveals and the individual policy descriptions do not.
This means that one can transform objectionable real-life experiments into acceptable experiments by avoiding objectionable policies.
![]()
Author feedback
Our policy (.htm) is to share drafts of blog posts that discuss someone else's work with them to solicit suggestions for things we should change prior to posting. We shared a draft with the authors of the PNAS paper. They caught a mislabeled item in the figure, and suggested a few word changes to increase accuracy in the description of their stimuli. Most importantly, they object to characterizing their analyses as having a problem and to characterizing our re-analysis as fixing that problem. They prefer the following characterization, that we ”conducted an additional empirical exercise that produced data that was then combined with some of their previously collected data to generate a different conclusion.” They approved that we include this quoted text.
- We asked MTurk participants (N=99) to evaluate the A and B policies in all 7 scenarios (but not the experiments over A and B). We computed for each scenario the within-person correlation between the rating of Policy A and Policy. Across the 7 scenarios it was r=.33. We then obtained random draws from the Normal distribution that were correlated r=.33. We converted these drawn values to quantiles and took such quantiles from the original A and B samples. The figure caption reports robustness to considering r=.5 and r=.2. This reliance on normal random draws to generate other distributions is known as NORTA (‘NORmal To Anything’). [↩]
- Detailed caption for Figure 1.
Average acceptability of policies A and B (black and white circles respectively), and of the experiment (gray circle), reproduce results in their Table 1. The acceptability of the worst arm is computed by randomly pairing observations between A & B, inducing the correlation within pair that we obtained in new data: r(A,B)=.33. For each of the seven studies, 10,000 pairs (with replacement) were formed. The lowest rated policy was computed within each pair, and averaged across them. This is the estimated average acceptability of the worst arm. Vertical lines depict 95% (bootstrapped) confidence intervals. [↩] - Discussion of implications of an A/B test revealing all policies available:
It does seem plausible to us that an experiment may be objected to because it reveals the alternative policy that could be pursued, while the direct implementation of either policy would not. For example, people may favor more vacation days for teachers, but not when they realize it comes at the expense of a $2000 bonus (and vice versa) and this tradeoff is more likely to be noticed if an experiment is run, where both policies are tested, than if the organization just implements one of them. However:
1) In practice, none of the famous cases where experiments were controversial (e.g., Facebook .htm, OKCupid .htm) arose because the A/B test revealed the two alternative courses of action. Rather, they were objectionable because they included policies that were objectionable on their own (e.g., lying to customers about how good a match they had with a potential date).
2) In the PNAS paper, all the scenarios we found through our re-analysis not to actually show experiment aversion, did reveal the two policies only in the A/B test, and not in the individual policy conditions. Thus, this possible mechanism behind opposition to A/B tests, if it exists, does not seem to be too strong.
3) The prototypical A/B test, and prototypical clinical trial, involves A=status-quo vs. B=new intervention. So the prototypical policy experiment does not reveal new information, for the counterfactual is as transparent to those evaluating B as to those evaluating the A/B test.
4) Knowing the opportunity cost of a policy is not sufficient to cause opposition to that policy. For example, in all studies in our paper people knew the counterfactual policy that could be implemented, and nevertheless, as long as the policies did not cause harm, even when they lead to unequal outcomes, choosing one policy over the other, or running an experiment, proved acceptable.
Given all this, we intuit that for the revelation of the alternative course of action to cause the experiment to be objectionable what's required is that choosing between A and B is seen as immoral or objectionable. This is a rare situation, but it is present in what we refer to as the 8th and 9th scenarios in the PNAS paper, the only two where experiment aversion persists after conducting our re-analysis assuming a correlation of r(A,B) = .33 (although, we did not collect new data for these scenarios). [↩] - We don't know if this qualifies as an illegal clinical trial or not, and presumably, neither do most respondents.
 [↩]
[↩]