In this second installment of Data Replicada, we report two attempts to replicate a study in a recently published Journal of Consumer Research (JCR) article entitled, “Wine for the Table: Self-Construal, Group Size, and Choice for Self and Others” (.htm).
Imagine that you are in a monthly book club and it is your job to select books for the upcoming meetings. Further imagine that your book club members are equally divided between those who prefer fiction and those who prefer nonfiction. You personally prefer nonfiction. You could choose selfishly and select mostly nonfiction books, or you could less selfishly opt for a balanced reading list of fiction and nonfiction. In this kind of situation, when will you behave most selfishly?
In this JCR paper, the authors propose that the answer to this question depends on two variables: (1) whether people are considering their independent selves or interdependent selves, and (2) whether the size of the group is small or large. Paraphrasing from the abstract, the key finding can be summarized thusly:
- When people are considering their interdependent selves, they consistently make choices that balance self and others’ preferences, regardless of group size. They are relatively unselfish.
- When people are considering their independent selves, they make choices that balance self and others’ preferences when the group is small, but they make choices that more strongly reflect their own preferences when the group is large.
In other words, independent consumers who choose on behalf of large groups tend to choose more selfishly, whereas everyone else tends to choose less selfishly.
The JCR paper contains six studies, all of which were conducted on MTurk. We chose to try to replicate Study 3 because it seemed to have the best statistical evidence, as it was supported by the smallest p-value in the paper: t(239) = 2.20, p = .03 [1]. In this study (N = 250), participants were first primed to think of their independent or interdependent selves. They then imagined being in a book club of either four or ten people, and were asked to choose which seven books the club members would have to read, on a scale ranging from zero nonfiction books (seven fiction books) to seven nonfiction books (zero fiction books). Subsequently, the researchers assessed participants’ own preferences for nonfiction vs. fiction books.
The result was a three-way interaction among priming condition (independent vs. interdependent), group size condition (small vs. large), and participants’ relative preference for nonfiction books (continuously measured). When participants were primed with independence and imagined being in a larger book club, then their choice of whether to have the group read more nonfiction books was highly correlated with their own preference for nonfiction books. That is, they chose selfishly. But this correlation was smaller among participants who were primed with independence and imagined being in a small book club, and among participants who were primed with interdependence (regardless of the size of the book club).
We contacted the authors to request the exact materials and the output of some of their analyses. They were extremely forthcoming and polite, quickly and thoroughly responding to all of our many follow-up questions and requests. We are extremely grateful to the authors for their help, professionalism, and patience.
An Embarrassing Interlude
While writing up the results of our replication, we realized that our survey contained a potentially important typo in a choice option that was part of the key dependent variable (described in more detail below). After discovering this mistake, we notified the original authors, and then, after much deliberation, decided to run a second replication. We report the results of both replications below.
The Replications
In our first attempt, we set out to run a preregistered replication that had about three times the sample size of the original (N = 800 MTurkers). We preregistered to adhere to the original authors’ exclusion criteria, but we severely underestimated the number of participants who would meet these criteria [2]. We wound up with only 565 participants and an inconclusive result. So we decided to get an additional 800 participants and to combine the data from these two waves for analysis [3]. We therefore have two preregistrations for this replication attempt (wave 1: https://aspredicted.org/ni9xq.pdf ; wave 2: https://aspredicted.org/zi4ue.pdf). After all exclusions we wound up with a sample of 1,118 participants, about 4.5 times the sample size of the original study.
In our second attempt, we corrected the typo from the first attempt, and invited 2,000 unique MTurkers to participate. After exclusions, we wound up with 1,305 participants (https://aspredicted.org/gc74h.pdf).
In our replications, we used the same instructions, procedures, questions, and participant population as in the original study [4] [5]. You can access our Qualtrics surveys here (.qsf1, .qsf2), our materials here (.pdf), our data here (.csv), our codebook here (.xlsx), and our R code here (.R).
Participants completed a survey that was ostensibly comprised of two separate studies. The first “study” primed the independent vs. interdependent self by having participants count the number of pronouns in a paragraph that contained only singular pronouns (independent prime condition) or only plural pronouns (interdependent prime condition):
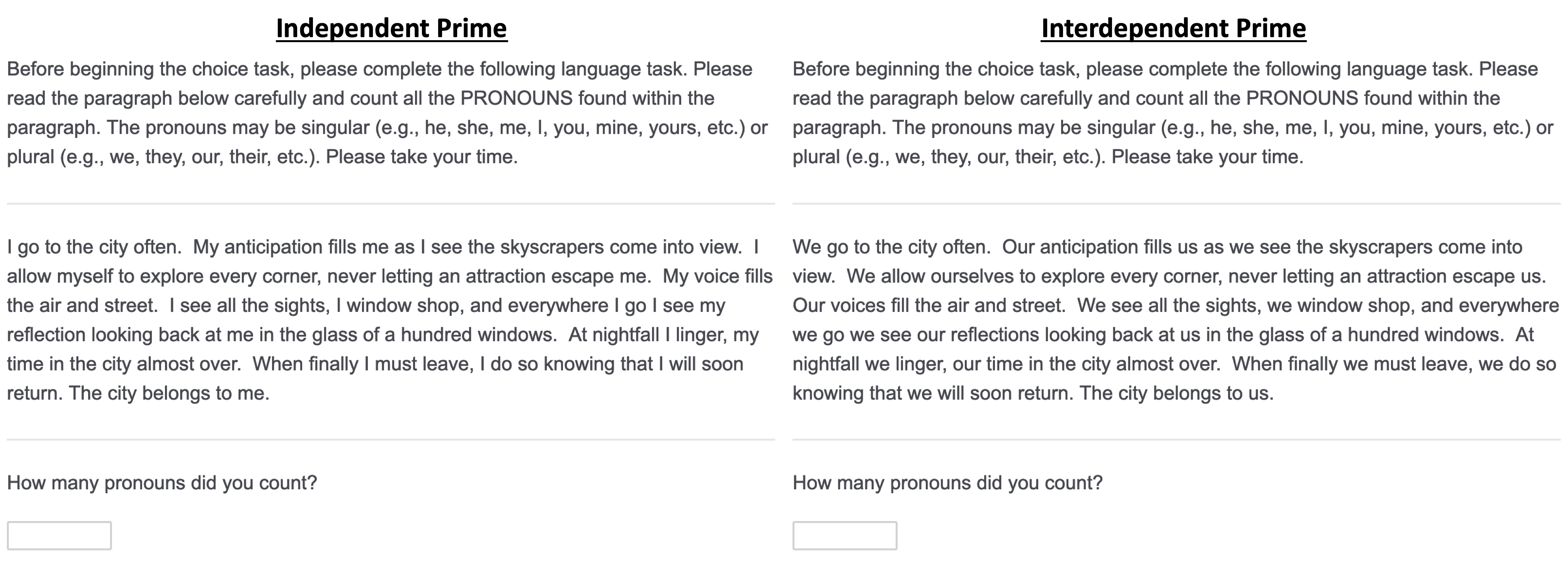
In the second “study,” participants read a scenario in which they imagined belonging to a book club. The book club consisted of either three other members (small group condition) or nine other members (large group condition):

Participants then learned that they were tasked with choosing books for the book club, that half of the book club prefers to read fiction and half prefers to read non-fiction, and to choose a book deal on behalf of the group. This was the key dependent variable, and this is where we bungled our first replication attempt:

Instead of Bookseller 4 offering four fiction books and three non-fiction books, we accidentally presented participants with an offering of four fiction books and four fiction books. This typo meant that one option now presented participants with more books than all of the other options. We do not know how much this affected the results, but it is possible it affected them quite a bit. That is why we ran Replication 2 [6].
After making this choice, participants then answered questions designed to assess how accountable they felt to others while making their choice, and then they indicated how often they read nonfiction books and how often they read fiction books. These three measures were used as covariates. Finally, participants indicated how much they like fiction vs. non-fiction books (on 7-point scales). We subtracted participants’ liking of fiction books from their liking of non-fiction books to compute a “preference for non-fiction” measure. In addition to the priming and group size manipulations, this represented the third key predictor in the main analysis.
So, in sum, this study had three independent variables:
- Priming condition: independent vs. interdependent (manipulated)
- Group size condition: small vs. large (manipulated)
- Preference for non-fiction over fiction books (measured)
The dependent variable is how many non-fiction books the participants chose on behalf of the book club (ranging from 0 to 7).
Results
Here are the original results, as well as our replication results. Keep in mind that in the graphs below, a more positive slope indicates greater selfishness.
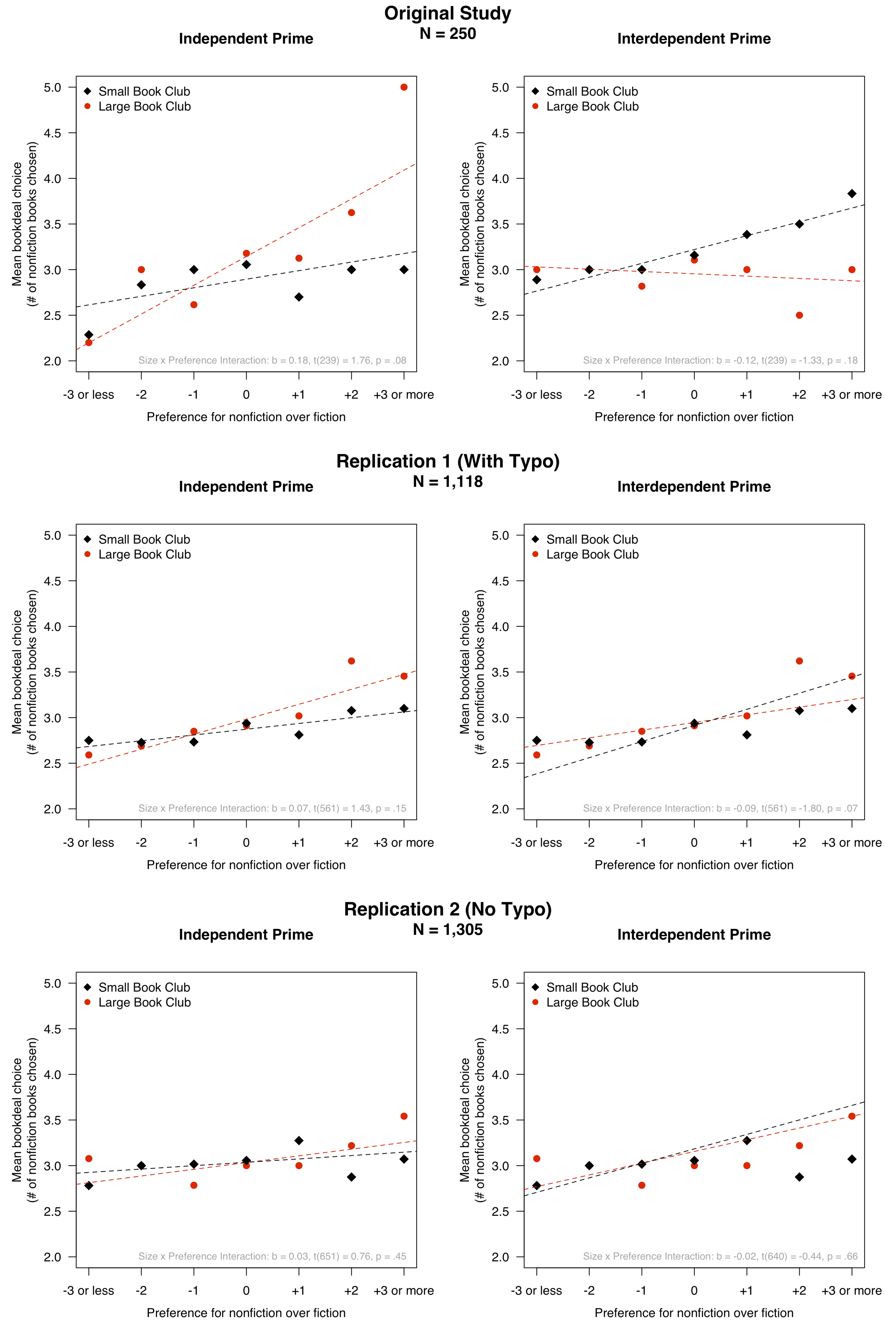
Let us first consider whether the original result was significant in the more highly powered replication attempts. In this case, the results are mixed. In the first replication attempt (with the typo), the three-way interaction among prime, group size, and preference for nonfiction was significant and in the same direction as in the original study: b = .162, SE = .070, p = .022. But in the second replication attempt (with no typo), that same interaction did not approach significance, though it was still in the same direction: b = .050, SE = .064, p = .432 [7] [8].
Although the 3-way interaction is in the same direction as the original, the nature of that interaction is not perfectly consistent with the original authors’ theorizing. Recall that their theory holds that the independent/large-group condition will be more selfish than the other three conditions, and that it will therefore exhibit the strongest positive relationship between book preference and book choice. But in the first replication attempt, we find that participants in the independent/large-group condition are no more selfish than those in the interdependent/small-group condition. And in the second replication attempt, we find that those in the two interdependent prime conditions are more selfish than those in the independent/large-group condition. Thus, to the extent that we are finding evidence for the authors’ three-way interaction, its form seems to be somewhat different from what was hypothesized.
Focusing again on the 3-way interaction, we can now consider what the replication results imply about the possible size of this effect, and about the sample size that would be required to detect it.
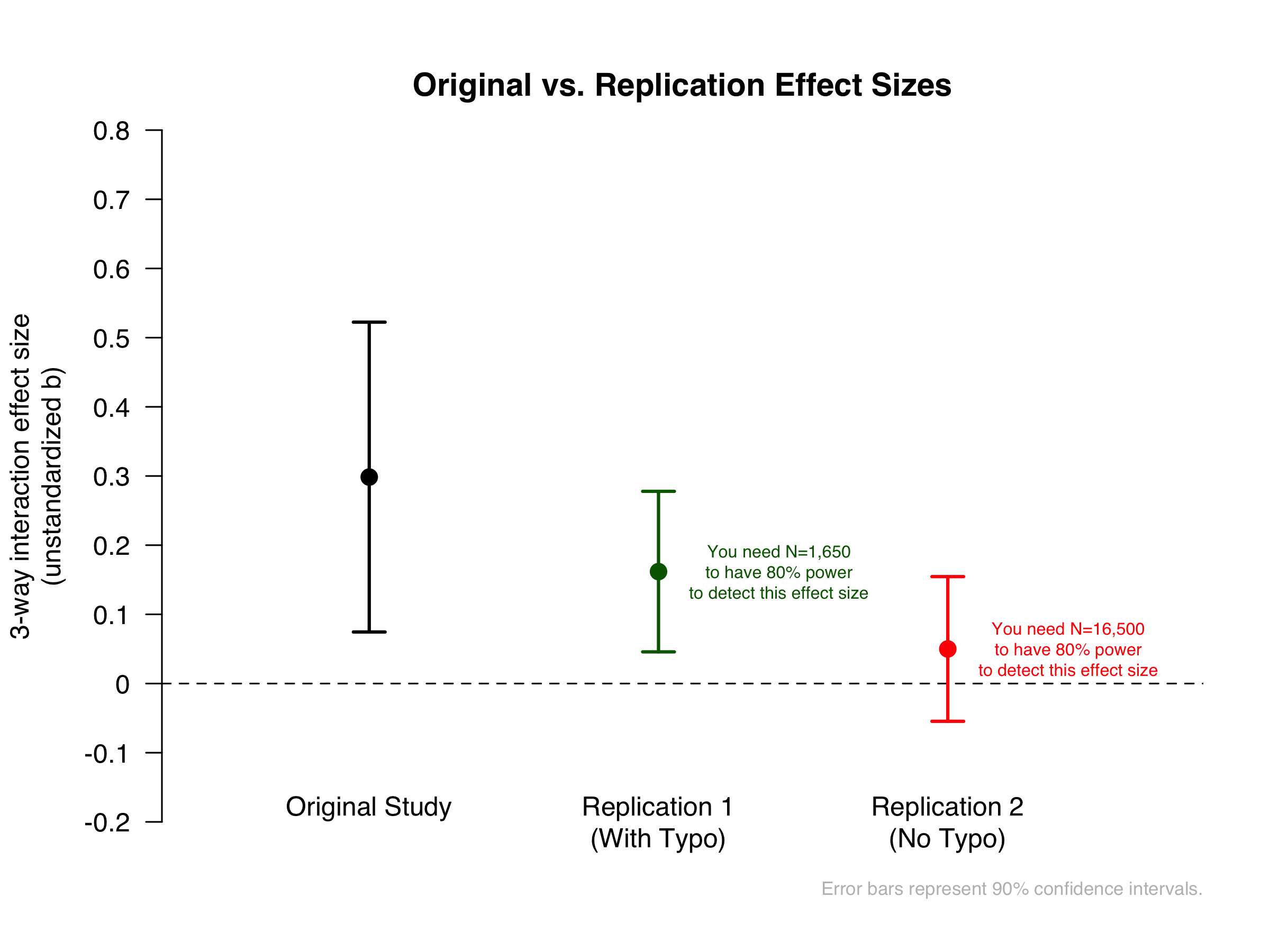
If the true effect size is equal to what we observed in Replication 1, then the original study (N = 250) would have had 22.4% power to detect it, and you would need N = 1,650 to have an 80% chance to detect it. If the true effect size is equal to what we observed in Replication 2, then the original study would have had 7.8% power to detect it, and you would need N = 16,500 to have an 80% chance to detect it.
In sum, our replications suggest that (1) the author’s predicted three-way interaction may or may not be a real effect, but (2) the effect is much smaller than what was reported in the original study, (3) the effect cannot be reliably observed using the original author’s sample size, and (4) the precise shape of this interaction is inconsistent across studies and not perfectly consistent with the authors’ theorizing. At least within this specific paradigm, there is not yet compelling evidence that those who are making decisions on behalf of a group are most selfish when the group is large and when they are considering their independent selves.
![]()
Author feedback
When we reached out to the authors for comments on the post, they responded as follows:
"Across all three studies, however, our perspective is that there is indeed an interaction between self-construal and group size that drives consumers' choices for self and others, though the size of this effect is not clear. We thank the Data Replicada team for their interest in our work, and we hope that these results will encourage future replications and research in this space, so that we may better understand the factors that drive such choices."
Footnotes.
- The other critical t-values were 1.87, 2.17, 1.99, 1.87, and 1.87, respectively. [↩]
- For a full description of how many participants we excluded and why, see this .pdf. [↩]
- Yes, this is a (fairly trivial) form of p-hacking; if we correct for it, then the critical p-value for Replication 1 is .047 instead of .022. [↩]
- There was only one noteworthy procedural difference. The original study contained a screen on which participants were presented with examples (and images) of newly released fiction and nonfiction books. Since that study was conducted in 2015 and ours was conducted in 2019, we had to decide whether to use the authors’ original books/images or to update them for 2019. We weren’t sure what to do, and so we decided to do both: half of the participants saw the original books/images and half saw books/images that we selected based on criteria the authors used to select their own stimuli. We collapse across this factor in the analyses presented below, but we should note that in our first replication the key result is only significant in the condition in which we presented the 2019 books. (In our second replication, the effect was somewhat stronger in the condition in which we presented the 2019 books: p = .396 vs. p = .780.) Perhaps it was important to update the books, or perhaps this is just chance. [↩]
- In the original study, the authors also conducted a test for mediation, using participants’ open-ended responses to one of the questions included in the survey. Although our data allow for us to conduct that mediation test, we have not done so, and in fact preregistered to ignore it. Interested readers can download the data and conduct that analysis themselves. [↩]
- We do know that this had at least some effect on the results: Participants were more likely to choose Bookseller 4’s offering in Replication 1 (73.1%) than in Replication 2 (60.5%), χ2(1) = 42.33, p < 10-10. [↩]
- The key analysis in this replication – a regression involving a three-way interaction among prime condition, group size, and preference for non-fiction books – has an inflated false-positive rate: 8.8% in Replication 1 and 7.2% in Replication 2. This is probably because of violations of assumptions that can emerge whenever a predictor is non-binary (e.g., outliers and/or heteroskedasticity), as in the case of the preference for nonfiction variable. We can fix it well enough if we use robust standard errors (Using robust standard errors reduced the false-positive rates to 5.2% in Replication 1 and 5.4% in Replication 2.). We do so in all analyses reported here, though we only preregistered this in Replication 2 (since we did not know about this problem before running Replication 1). Using robust standard errors appropriately increases the p-values that we report, but in this instance it did not change the significance of any of them. [↩]
- At the end of the study, we asked participants, “To your knowledge, have you ever participated in a past study on MTurk that asked you to imagine being in a bookclub and then to make choices on behalf of that bookclub?” (Possible answers: No, Maybe, Yes). Restricting the analyses to those participants who answered “No” to this question (N = 1,009 in Replication 1; N = 1,158 in Replication 2) makes the Replication 1 results a bit stronger (p = .004) and the Replication 2 results a bit weaker (p = .877). [↩]