Statistically significant findings are much more likely to be published than non-significant ones (no citation necessary). Because overestimated effects are more likely to be statistically significant than are underestimated effects, this means that most published effects are overestimates. Effects are smaller – often much smaller – than the published record suggests.
For meta-analysts the gold standard procedure to correct for this bias, with >1700 Google cites, is called Trim-and-Fill (Duval & Tweedie 2000, .pdf). In this post we show Trim-and-Fill generally does not work.
What is Trim-and-Fill?
When you have effect size estimates from a set of studies, you can plot those estimates with effect size on the x-axis and a measure of precision (e.g., sample size or standard error) on the y-axis. In the absence of publication bias this chart is symmetric: noisy estimates are sometimes too big and sometimes too small. In the presence of publication bias the small estimates are missing. Trim-and-Fill deletes (i.e., trims) some of those large-effect studies and adds (i.e., fills) small-effect studies, so that the plot is symmetric. The average effect size in this synthetic set of studies is Trim-and-Fill’s “publication bias corrected” estimate.
What is Wrong With It?
A known limitation of Trim-and-Fill is that it can correct for publication bias that does not exist, underestimating effect sizes (see e.g., Terrin et al 2003, .pdf). A less known limitation is that it generally does not correct for the publication bias that does exist, overestimating effect sizes.
The chart below shows the results of simulations we conducted for our just published "P-Curve and Effect Size" paper (SSRN). We simulated large meta-analyses aggregating studies comparing two means, with sample sizes ranging from 10-70, for five different true effect sizes. The chart plots true effect sizes against estimated effect sizes in a context in which we only observe significant (publishable) findings (R Code for this [Figure 2b] and all other results in our paper).
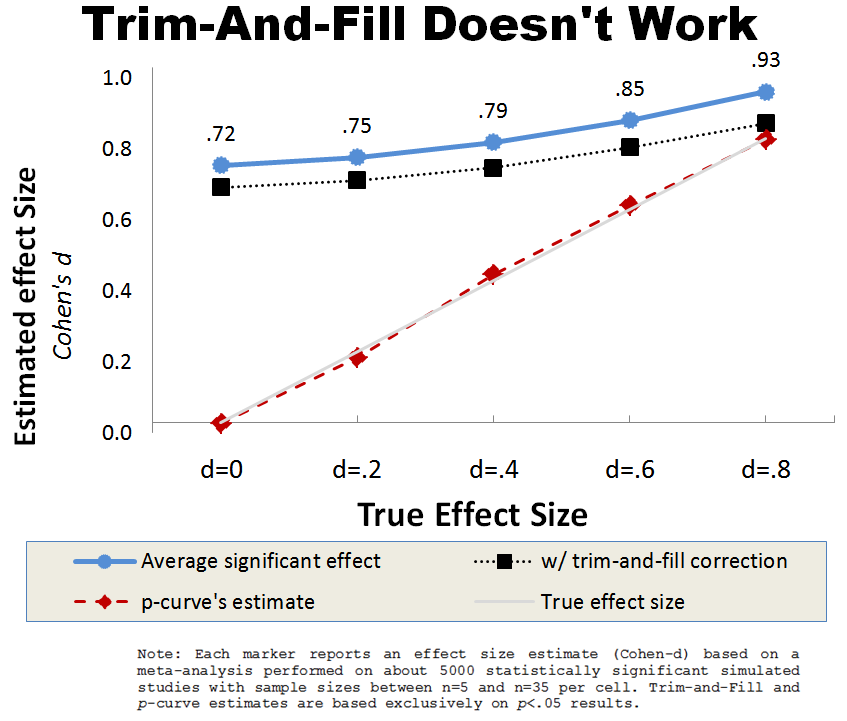
Start with the blue line at the top. That line shows what happens when you simply average only the statistically significant findings–that is, only the findings that would typically be observed in the published literature. As we might expect, those effect size estimates are super biased.
The black line shows what happens when you “correct” for this bias using Trim-and-Fill. Effect size estimates are still super biased, especially when the effect is nonexistent or small.
Aside: p-curve nails it.
We were wrong
Trim-and-Fill assumes that studies with relatively smaller effects are not published (e.g., that out of 20 studies attempted, the 3 obtaining the smallest effect size are not publishable). In most fields, however, publication bias is governed by p-values rather than effect size (e.g., out of 20 studies only those with p<.05 are publishable).
Until a few weeks ago we thought that this incorrect assumption led to Trim-and-Fill’s poor performance. For instance, in our paper (SSRN) we wrote
when the publication process suppresses nonsignificant findings, Trim-and-Fill is woefully inadequate as a corrective technique.” (p.667)
For this post we conducted additional analyses and learned that Trim-and-Fill performs poorly even when its assumptions are met–that is, even when only small-effect studies go unpublished (R Code). Trim-and-Fill seems to work well only when few studies are missing, that is, where there is little bias to be corrected. In situations when a correction is most needed, Trim-and-Fill does not correct nearly enough.
Two Recommendations
1) Stop using Trim-and-Fill in meta-analyses.
2) Stop treating published meta-analyses with a Trim-and-Fill “correction” as if they have corrected for publication bias. They have not.
![]()
Author response:
Our policy at Data Colada is to contact authors whose work we cover, offering an opportunity to provide feedback and to comment within our original post. Trim-and-Fill was originally created by Sue Duval and the late Richard Tweedie. We contacted Dr. Duval and exchanged a few emails but she did not provide feedback nor a response.