Methods people often say – in textbooks, task forces, papers, editorials, over coffee, in their sleep – that we should focus more on estimating effect sizes rather than testing for significance.
I am kind of a methods person, and I am kind of going to say the opposite.
Only kind of the opposite because it is not that we shouldn’t try to estimate effect sizes; it is that, in the lab, we can’t afford to.
The sample sizes needed to estimate effect sizes are too big for most researchers most of the time.
With n=20, forget it
The median sample size in published studies in Psychology is about n=20 per cell. [1] There have been many calls over the last few decades to report and discuss effect size in experiments. Does it make sense to push for effect size reporting when we run small samples? I don’t see how.
Arguably the lowest bar for claiming to care about effect size is so to distinguish among Small, Medium, and Large effects. And with n=20 we can’t do even that.
Cheatsheet: I use Cohen’s d to index effect size. d is by how many standard deviations the means differ. Small is d=.2, Medium d=.5 and Large d=.8.
The figure below shows 95% confidence intervals surrounding Small, Medium and Large estimates when n=20 (see simple R Code).
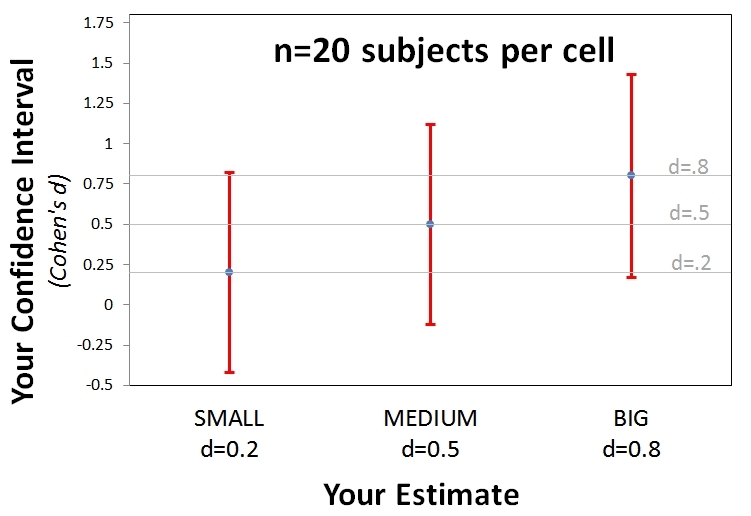
Whatever effect we get, we will not be able to rule out effects of a different qualitative size.
Four-digit n’s
It is easy to bash n=20 (please do it often). But just how big an n do we need to study effect size?
I am about to show that the answer has four-digits.
It will be rhetorically useful to consider a specific effect size. Let’s go with d=.5. You need n=64 per cell to detect this effect 80% of the time.
If you run the study with n=64, then you will get a confidence interval that will not include zero 80% of the time, but if your estimate is right on the money at d=.5, that confidence interval still will include effects smaller than Small (d<.2) and larger than Large (d>.8). So n=64 is fine for testing whether the effect exists, but not for estimating its size.
Properly powered studies teach you almost nothing about effect size. [2]
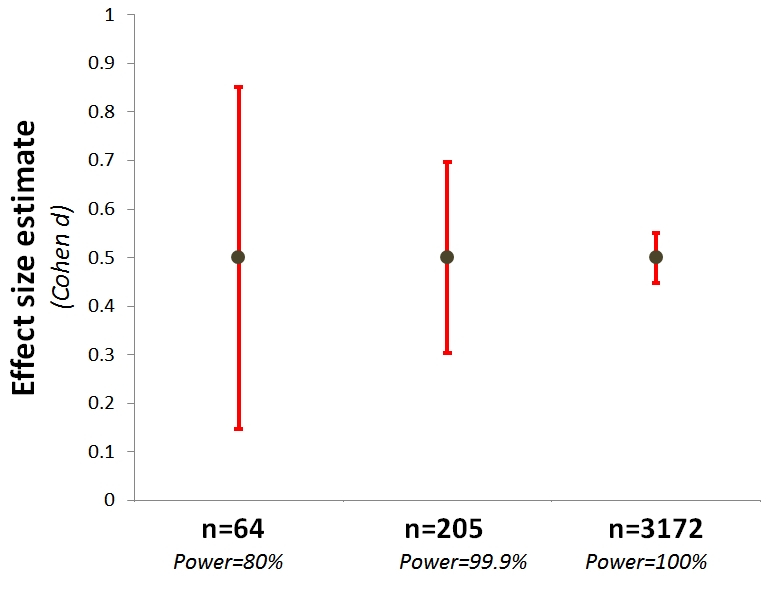
What if we go the extra mile, or three, and power it to 99.9%, running n=205 per cell. This study will almost always produce a significant effect, yet the expected confidence interval is massive, spanning a basically small effect (d=.3) to a basically large effect (d=.7).
To get the kind of confidence interval that actually gives confidence regarding effect size, one that spans say ±0.1, we need n=3000 per cell. THREE-THOUSAND. (see simple R Code) [3]
In the lab, four-digit per-cell sample sizes are not affordable.
Advocating a focus on effect size estimation, then, implies advocating for either:
1) Leaving the lab (e.g., mTurk, archival data). [4]
2) Running within-subject designs.
Some may argue effect size is so important we ought to do these things.
But that’s a case to be made, not an implication to be ignored.
UPDATE 2014 05 08: A commentary on this post is available here
![]()
- Based on the degrees of freedom reported in thousands of test statistics I scraped from Psych Science and JPSP[↩]
- Unless you properly power for a trivially small effect by running a gigantic sample[↩]
- If you run n=1000 the expected confidence interval spans d=.41 and d=.59[↩]
- One way to get big samples is to combine many small samples. Whether one should focus on effect size in meta-analysis is not something that seems controversial enough to be interesting to discuss[↩]