In the paper “One Swallow Doesn’t Make A Summer: New Evidence on Anchoring Effects”, forthcoming in the AER, Maniadis, Tufano and List attempted to replicate a classic study in economics. The results were entirely consistent with the original and yet they interpreted them as a “failure to replicate.” What went wrong?
This post answers that question succinctly; our new paper has additional analyses.
Original results
In an article with >600 citations, Ariely, Loewenstein, and Prelec (2003) showed that people presented with high anchors (“Would you pay $70 for a box of chocolates?”) end up paying more than people presented with low anchors (“Would you pay $20 for a box of chocolates?”). They found this effect in five studies, but the AER replication reran only Study 2. In that study, participants gave their asking prices for aversive sounds that were 10, 30, or 60 seconds long, after a high (50¢), low (10¢), or no anchor.
Replication results
comparing only the 10-cent and 50-cent anchor conditions, we find an effect size equal to 28.57 percent [the percentage difference between valuations], about half of what ALP found. The p-value […] was equal to 0.253” (p. 8).
So their evidence is unable to rule out the possibility that anchoring is a zero effect. But that is only part of the story. Does their evidence also rule out a sizable anchoring effect? It does not. Their evidence is consistent with an effect much larger than the original.
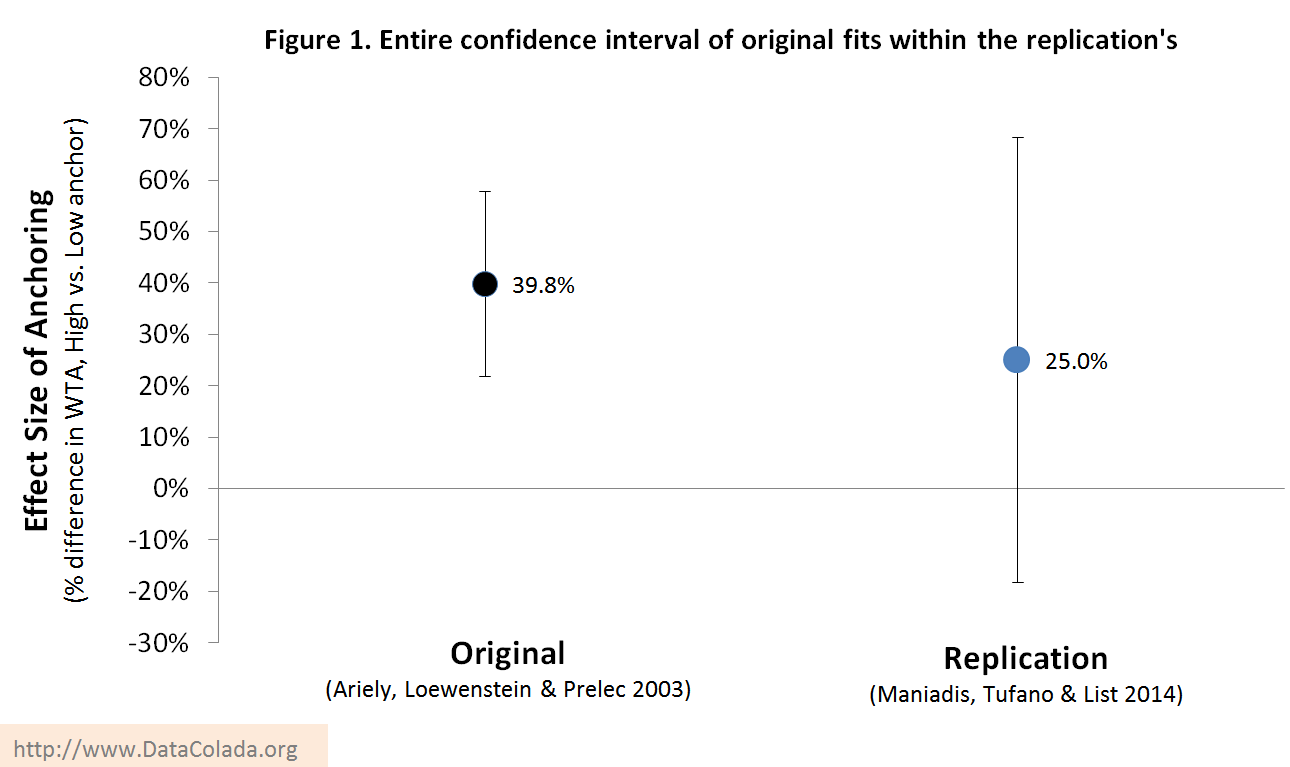
Those calculations use Maniadis et al.’s definition of effect size: % difference in valuations (as quoted above). An alternative is to divide the differences of means by the standard deviation (Cohen’s d). Using this metric the Replication’s effect size is more markedly different from the Original’s, d=.94 vs. d=.26 . However, the 95% confidence interval for the Replication includes effects as big as d=.64, midway between medium and large effects. Whether we examine Maniadis et al.’s operationalization of effect size, then, or Cohen’s d, we arrive at the same conclusion: the Replication is too noisy to distinguish between a nonexistent and a sizable anchoring effect.
Why is the Replication so imprecise?
In addition to having 12% fewer participants, nearly half of all valuations are ≤10¢. Even if anchoring had a large percentage effect, one that doubles WTA from 3¢ to 6¢, the tendency of participants to round both to 5¢ makes it undetectable. And there is the floor effect: valuations so close to $0 cannot drop. One way around this problem is to do something economists do all the time: Express the effect size of one variable (How big is the impact of X on Z?) relative to the effect size of another (it is half the effect of Y on Z). Figure 2 shows that, in cents, both the effect of anchoring and duration is smaller in the replication, and that the relative effect of anchoring is comparable across studies. 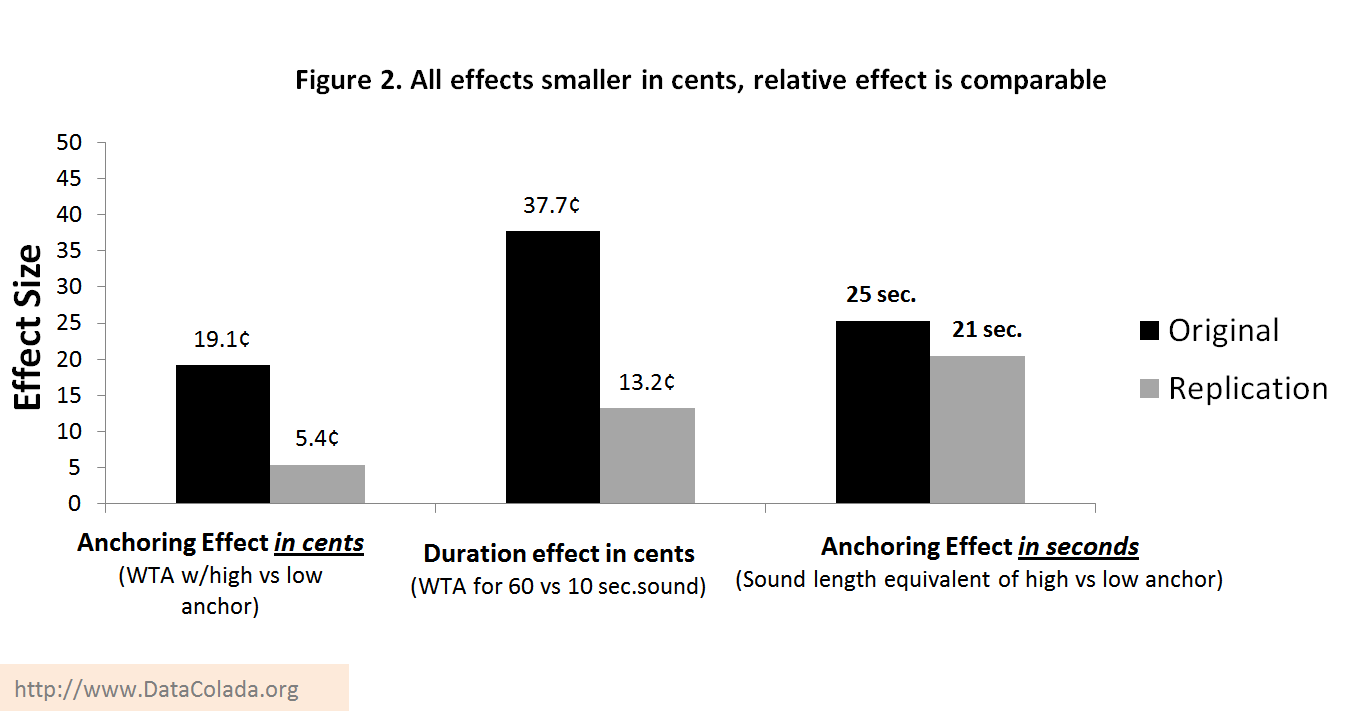
p-curve
The original paper had five studies, four were p<.01, the fifth p<.02. When we submit these p-values to p-curve we can empirically examine the fear expressed by the replicators that the original finding is false-positive. The results strongly reject this possibility; selective reporting is an unlikely explanation for the original paper, p<.0001.
Some successful replications
Every year Uri runs a replication of Ariely et al.’s Study 1 in his class. In an online survey at the beginning of the semester, students write down the last two digits of their social-security-number, indicate if they would pay that amount for something (this semester it was for a ticket to watch Jerry Seinfeld live on campus), and then indicate the most they would pay. Figure 3 has this year’s data:
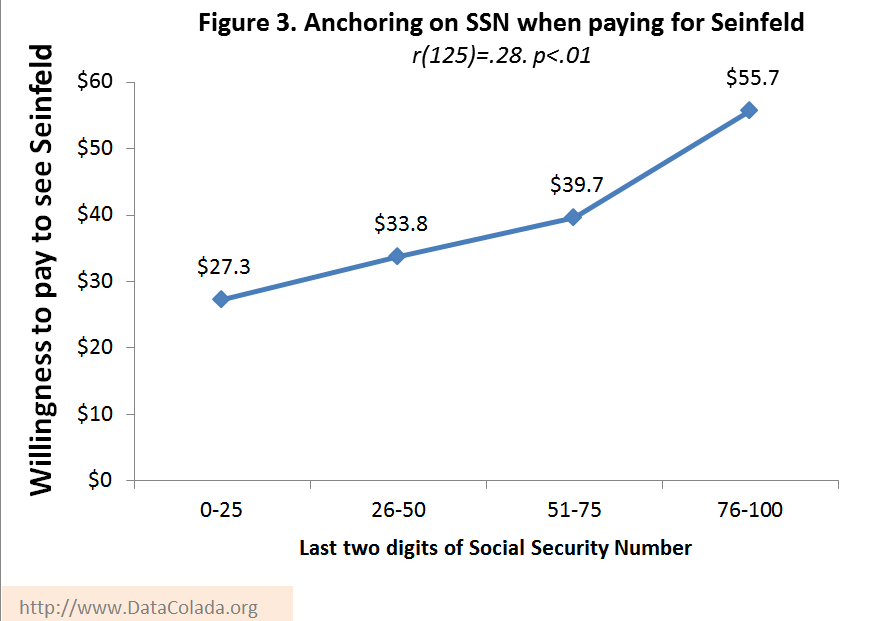
We recently learned that SangSuk Yoon, Nathan Fong and Angelika Dimoka successfully replicated Ariely et al.’s Study 1 with real decisions (in contrast to this paper).
Concluding remark
We are not vouching for the universal replicability of Ariely et al here. It is not difficult to imagine moderators (beyond floor effects) that attenuate anchoring. We are arguing that the forthcoming “failure-to-replicate” anchoring in the AER is no such thing.
note: When we discuss others’ work at DataColada we ask them for feedback and offer them space to comment within the original post. Maniadis, Tufano, and List provided feedback only for our paper and did not send us comments to post here.