In the fifth installment of Data Replicada, we report our attempt to replicate a recently published Journal of Consumer Research (JCR) article entitled, “The Influence of Product Anthropomorphism on Comparative Choice” (.html).
A product becomes “anthropomorphized” when it is imbued with human-like features, such as a face or a name. For example, this camera, which was presented in this article's Study 1B, is anthropomorphized:

The article begins with the premise that “people usually form an integrated impression of [an] entire person rather than seeing this person as consisting of separate traits.” The authors then propose that human-like products will also be judged in this way: Consumers will be more likely to use a holistic process (vs. an attribute-by-attribute comparison) to judge anthropomorphized products.
This JCR paper contains six studies. We chose to replicate Study 2 (N = 101) because it was the only study run on MTurk. In this study, participants considered two laptops. In one condition, the laptops were given human-like qualities (described below). In the other condition, they were not. Each laptop had a star rating for each of three dimensions. One laptop was better overall (i.e., it had more total stars), while the other laptop was better on more dimensions (i.e., it had more stars on two out of three dimensions, but fewer stars overall). The authors found that people were more likely to choose the laptop that had more total stars when the laptops were more human-like.
We contacted the authors to request the materials needed to conduct a replication. They were extremely forthcoming and polite. They shared the original Qualtrics file that they used to conduct that study, and we used it to conduct our replications. We are very grateful to them for their help and professionalism.
The Replications
We ran two replications. The first was run on MTurk. The authors were concerned that we not recruit any participants who had completed similar studies. To facilitate that goal, they supplied us with a list of 11,643 MTurk workers (101 of which had been in the original experiment) for us to exclude from our investigation. We did so, but then worried that delving so deep into the MTurk participant pool may have caused us to reach a very different population and therefore might weaken the results. So we ran a second, identical replication on Prolific Academic.
In both preregistered replications (https://aspredicted.org/mg4gu.pdf; https://aspredicted.org/d92dd.pdf), we used the same survey as in the original study, and therefore the same instructions, procedures, images, and questions. These studies did not deviate from the original study in any discernible way, except that our consent form was necessarily different, and we had about 5.5 times the original sample size (Ns = 562 in our MTurk replication and 584 in our Prolific replication) [1]. You can access our Qualtrics surveys here (.qsf1; .qsf2), our materials here (.pdf), our data here (.csv1; .csv2), our codebook here (.xlsx), and our R code here (.R).
In each study, we asked respondents to choose between two laptops. In the Anthropomorphism condition, participants were asked to “treat each of the two laptops as a person who is introducing him/herself to you, and then make the decision.” In the Control condition, participants were simply told to “process the following information, and then make the decision.” Then, on the following screen, participants were faced with the choice [2]:
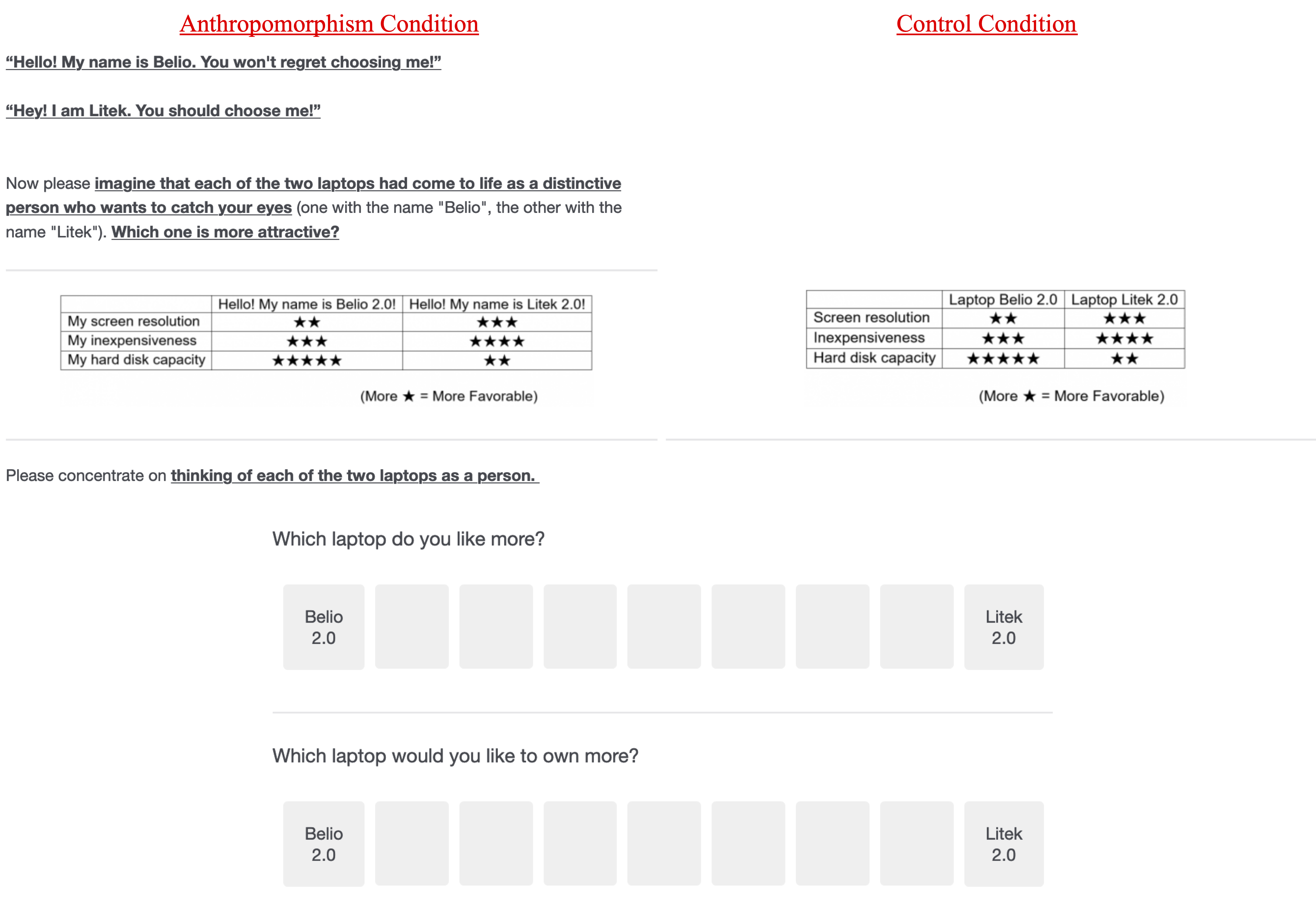
Those two measures were averaged and coded so that higher numbers indicated a stronger preference for the laptop with more total stars (i.e., a stronger preference for Belio).
Before presenting the results, it is worth mentioning that this design contains some small potential confounds. For example, only in the Anthropomorphism condition were people told that they “won’t regret choosing” the laptop with more stars (i.e., Belio). We did not undo these confounds in these studies, because we wanted to remain faithful to the original. Also, relying on nothing but our fallible intuitions, we didn’t think that those potential confounds would matter very much.
Results
Here are the original vs. replication results:
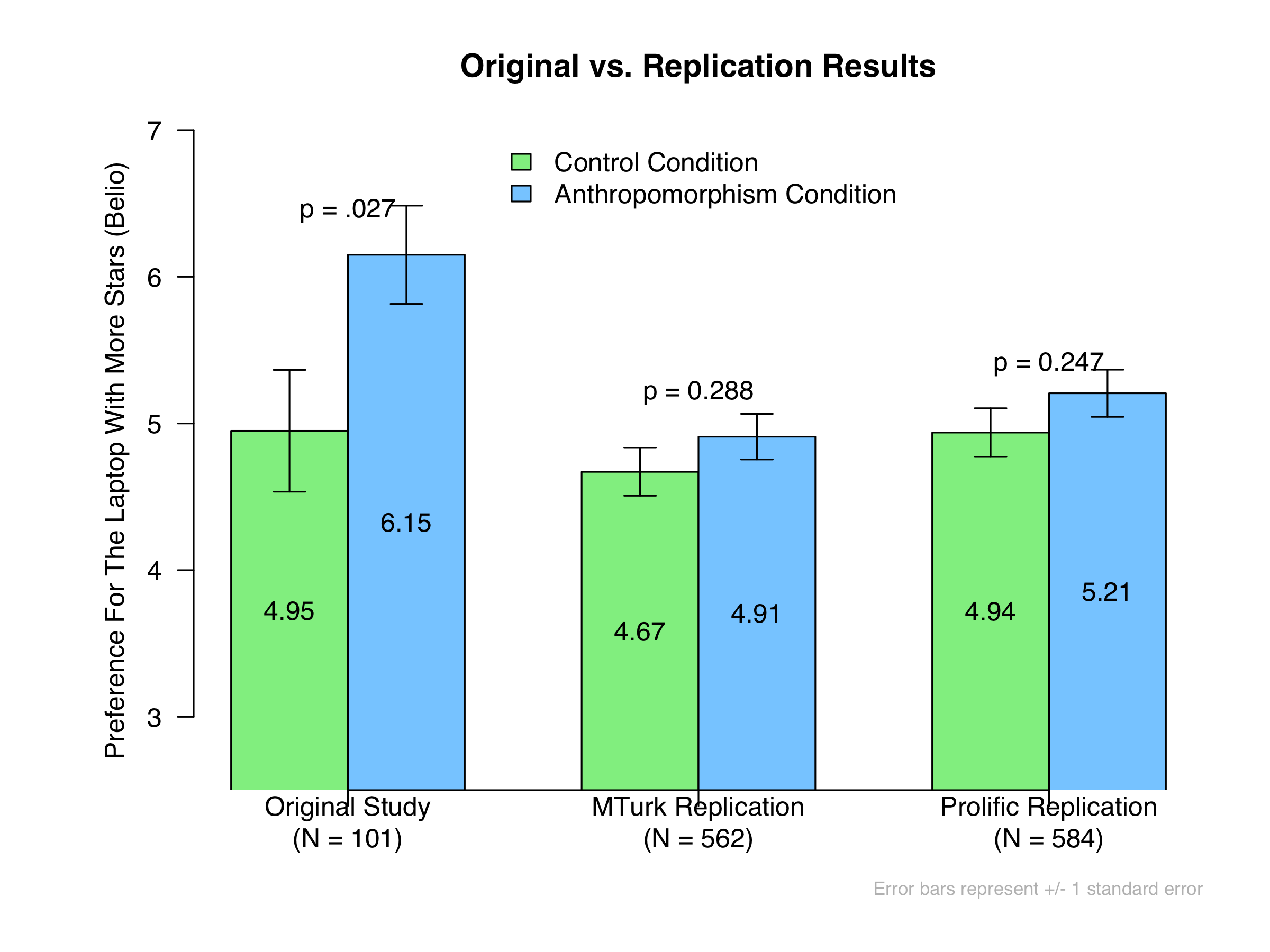 As you can see, the results of the replications were in the right direction but were nonsignificant. And the effect sizes that we observed – d = .09 in the MTurk replication and d = .10 in the Prolific replication – were much smaller than the effect size reported in the original study (d = .45). These results cannot be explained by the ineffectiveness of our manipulation (see this footnote: [3]), or by our delving so deep into the MTurk participant pool [4]. Indeed, perhaps the most noteworthy finding is that the two replications produced extremely similar results, despite coming from different online populations.
As you can see, the results of the replications were in the right direction but were nonsignificant. And the effect sizes that we observed – d = .09 in the MTurk replication and d = .10 in the Prolific replication – were much smaller than the effect size reported in the original study (d = .45). These results cannot be explained by the ineffectiveness of our manipulation (see this footnote: [3]), or by our delving so deep into the MTurk participant pool [4]. Indeed, perhaps the most noteworthy finding is that the two replications produced extremely similar results, despite coming from different online populations.
One conclusion could be that the original effect does not truly exist, and the original finding was a false positive. Our evidence is consistent with that. Our evidence is also consistent with the possibility that the original effect might exist but is considerably smaller than what was found in the original. Indeed, combining the p-values of these two replications generates a marginally significant overall effect (p = .071). Nevertheless, it is important to highlight two things. First, any real effect could exist because of the aforementioned confounds. Second, our results imply that the original study was underpowered to around 8%, indicating that its sample size was simply not large enough to detect the effects that we have observed. Indeed, instead of needing 101 participants in the original study, our investigation suggests you’d need at least 3,400.
Conclusion
In sum, using 5.5 times the sample size as the original study, we do not find significant evidence that adorning laptops with human-like features makes consumers more likely to choose the one that has more total stars (instead of the one that is better on more dimensions).
![]()
Author feedback
When we reached out to the authors for comments on the post, they responded as follows:
"We would like to thank the Data Replicada team for their interest in our work. In general, we were encouraged to see that both replications from different online platforms produced the predicted pattern of the original study and that 'combining the p-values of these two replications generates a marginally significant overall effect (p = .071).'
Because the replications were conducted around five years after the original study (early 2015), various factors may come into play and undermine the observed effect size. First, a growing body of research has suggested that MTurk’s data quality has decreased substantially in recent years, especially after 2018 (e.g., Chmielewski & Kucker, 2020). Problems like workers’ nonnaïveté, fake IP, dishonesty, and carelessness, etc. (e.g., Buhrmester, Talaifar, & Gosling, 2018) may reduce the observed effect size (e.g., Hauser, Paolacci, & Chandler, 2018). Other online crowdsourcing platforms (e.g., Prolific) may also encounter such issues, given the noticeable growth of their popularity and the overlaps of workers across platforms. And discussions about various possible solutions increased accordingly, such as including validity indicators, checking time per item, and IP checking package (e.g., Kennedy et al., 2020), to improve the effectiveness of crowdsourcing platforms. Relatedly, bigger samples are widely acknowledged in recent years, and we totally support such a practice.
Second, consumers’ criteria in making decisions for time-sensitive products, like tech products (e.g., laptops in this study), may change considerably over time, such as their emphases on and perceptions of different attributes. The results then actually intrigue a very interesting question. While an effect can theoretically persist over time, the specific experimental instructions (e.g., the stimuli design) may need updates to accurately reflect the effect and underlying theory.
Finally, we thank again the Data Colada team for the efforts. We are glad that the basic pattern of our original study appeared consistently, and the replication deepened our understanding in possible changes of the observed effect size. We can always learn and benefit from such efforts."
Footnotes.
- We followed the policy and advice of the original authors, and pre-registered to exclude participants who answered “yes” to a question asking them whether they have completed similar studies before in the past. This resulted in 41 exclusions in the MTurk replication, and 22 exclusions in the Prolific replication. The sample sizes reported here are the ones included in our final analyses. [↩]
- Note that, just like the authors, we counterbalanced the order of the laptops and the order of the attribute names, but not the order of the stars, nor whether “Belio” was the laptop with more stars (i.e., “Belio” was always the laptop with more stars.) [↩]
- As in the original study, we asked all respondents to rate, on 9-point scales, the extent to which each of the laptops “sounds like a person,” “seems as if it has free will,” and “seems as if it has intentions.” We averaged these measures, and then tested whether the laptops were perceived to be more human-like in the Anthropomorphism condition. They were: d = .68, t(560) = 8.36, p < .001, in the MTurk replication; d = .99, t(582) = 11.92, p < .001, in the Prolific replication. The effect size we observed in the Prolific replication is very close to the one reported in the original study (d = 1.07). In short, the manipulation seems to have worked, at least as captured by these measures. [↩]
- These data were collected before COVID-19 upended American life – December 2019 (MTurk) and mid-February 2020 (Prolific) – and so the pandemic cannot explain these findings either. [↩]