In a recent working paper, Carter et al (htm) proposed that one can better correct for publication bias by including not just p<.05 results, the way p-curve does, but also p>.05 results [1]. Their paper, currently under review, aimed to provide a comprehensive simulation study that compared a variety of bias-correction methods for meta-analysis.
Although the paper is well written and timely, the advice is problematic. Incorporating non-significant results into a tool designed to correct for publication bias requires one to make assumptions about how difficult it is to publish each possible non-significant result. For example, one has to make assumptions about how much more likely an author is to publish a p=.051 than a p=.076, or a p=.09 in the wrong direction than a p=.19 in the right direction, etc. If the assumptions are even slightly wrong, the tool’s performance becomes disastrous [2]
Assumptions and p>.05s
The desire to include p>.05 results in p-curve type analyses is understandable. Doing so would increase our sample sizes (of studies), rendering our estimates more precise. Moreover, we may be intrinsically interested in learning about studies that did not get to p<.05.
So why didn’t we do that when we developed p-curve? Because we wanted a tool that would work well in the real world. We developed a good tool, because the perfect tool is unattainable.
While we know that the published literature generally does not discriminate among p<.05 results (e.g., p=.01 is not perceptibly easier to publish than is p=.02), we don’t know how much easier it is to publish some non-significant results rather than others.
The downside of p-curve focusing only on p<.05 is that p-curve can “only” tell us about the (large) subset of published results that are statistically significant. The upside is that p-curve actually works.
All p>.05 are not created equal
The simulations reported by Carter et al. assume that all p>.05 findings are equally likely to be published: a p=.051 in the right direction is as likely to be published as a p=.051 in the wrong direction. A p=.07 in the right direction is as likely to be published as a p=.97 in the right direction. If this does not sound implausible to you, we recommend re-reading this paragraph.
Intuitively it is easy to see how getting this assumption wrong will introduce bias. “Imagine” that a p=.06 is easier to publish than is a p=.76. A tool that assumes both results are equally likely to be published will be naively impressed when it sees many more p=.06s than p=.76s, and it will fallaciously conclude there is evidential value when there isn’t any.
A calibration
We ran simulations matching one of the setups considered by Carter et al., and assessed what happens if the publishability of p>.05 results deviated from their assumptions (R Code). The black bar in the figure below shows that if their fantastical assumption were true, the tool would do well, producing a false-positive rate of 5%. The other bars show that under some (slightly) more realistic circumstances, false-positives abound.
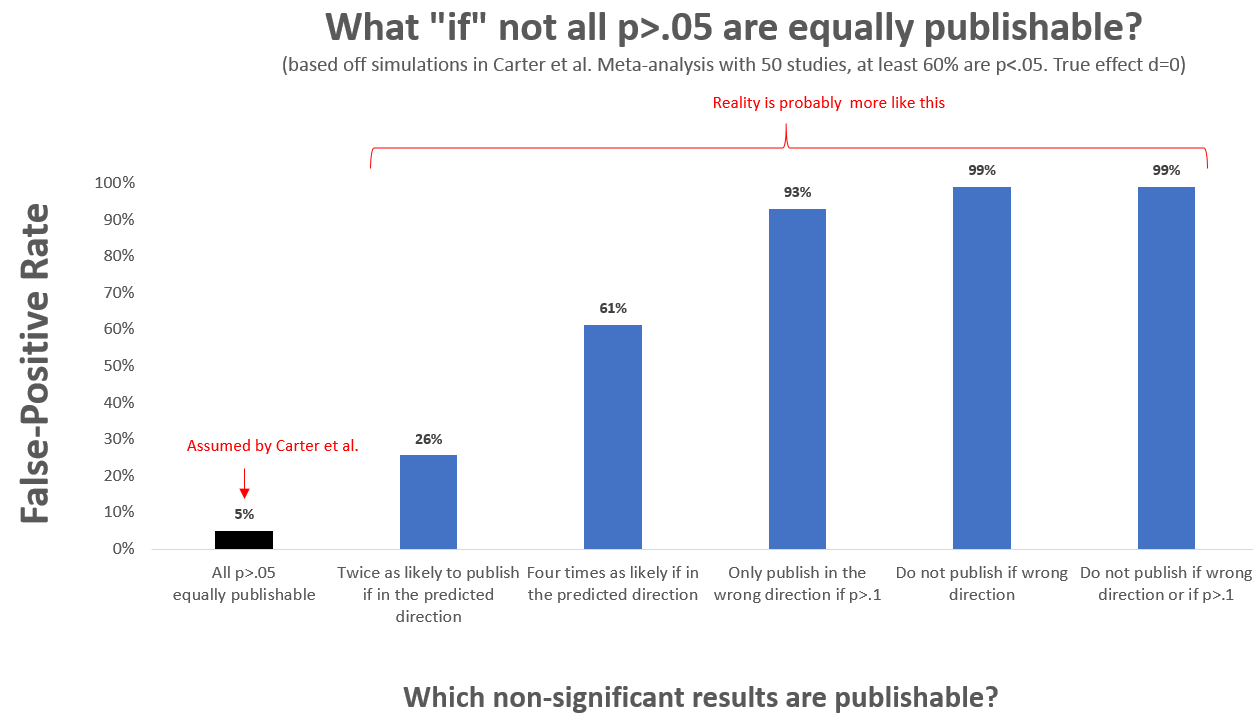 One must exclude p>.05
One must exclude p>.05
It is obviously not true that all p>.05s are equally publishable. But no alternative assumption is plausible. The mechanisms that influence the publication of p>.05 results are too unknowable, complex, and unstable from paper to paper, to allow one to make sensible assumptions or generate reasonable estimates. The probability of publication depends on the research question, on the authors’ and editors’ idiosyncratic beliefs and standards, on how strong other results in the paper are, on how important the finding is for the paper’s thesis, etc. Moreover, comparing the 2nd and 3rd bar in the graph above, we see that even minor quantitative differences in a face-valid assumption make a huge difference.
P-curve is not perfect. But it makes minor and sensible assumptions, and is robust to realistic deviations from those assumptions. Specifically, it assumes that all p<.05 are equally publishable regardless of what exact p-value they have. This captures how most researchers perceive publication bias to occur (at least in psychology). Its inferences about evidential value are robust to relatively large deviations from this assumption (e.g., if researchers start aiming for p<.045 instead of p<.05, or even p<.035, or even p<.025, p-curve analysis, as implemented in the online app (.htm), will falsely conclude there is evidential value when the null is true, no more than 5% of the time. See our “Better P-Curves” paper (SSRN)).
Conclusion
With p-curve we can determine whether a set of p<.05 results have evidential value, and what effect we may expect in a direct replication of those studies. Those are not the only questions you may want to ask. For example, traditional meta-analysis tools ask what is the average effect of all of the studies that one could possibly run (whatever that means; see Colada[33]), not just those you observe. P-curve does not answer that question. Then again, no existing tool does. At least not even remotely accurately.
P-curve tells you “only” this: If I were to run these statistically significant studies again, what should I expect?
![]()
Author feedback.
We shared a draft of this post with Evan Carter, Felix Schönbrodt, Joe Hilgard and Will Gervais. We had an incredibly constructive and valuable discussion, sharing R Code back and forth and jointly editing segments of the post.
We made minor edits after posting responding to readers’ feedback. The original version is archived here .htm.
Footnotes.- When applying p-curve to estimate effect size, it is extremely similar to following the “one-parameter-selection-model” by Hedges 1984 (.htm). [↩]
- Their paper is nuanced in many sections, but their recommendations are not. For example, they write in the abstract, “we generally recommend that meta-analysis of data in psychology use the three-parameter selection model.”[↩]