Sometimes we selectively report the analyses we run to test a hypothesis.
Other times we selectively report which hypotheses we tested.
One popular way to p-hack hypotheses involves subgroups. Upon realizing analyses of the entire sample do not produce a significant effect, we check whether analyses of various subsamples — women, or the young, or republicans, or extroverts — do. Another popular way is to get an interesting dataset first, and figure out what to test with it second [1].

For example, a researcher gets data from a spelling bee competition and asks: Is there evidence of gender discrimination? How about race? Peer-effects? Saliency? Hyperbolic discounting? Weather? Yes! Then s/he writes a paper titled “Weather & (Spelling) Bees” as if that were the only hypothesis tested [2]. The odds of a p<.05 when testing all these hypotheses is 26% rather than the nominal 5% [3].
Robustness checks involve reporting alternative specifications that test the same hypothesis. Because the problem is with the hypothesis, the problem is not addressed with robustness checks [4].
Example: Odd numbers and the horoscope
To demonstrate the problem I conducted exploratory analyses on the 2010 wave of the General Social Survey (GSS) until discovering an interesting correlation. If I were writing a paper about it, this is how I may motivate it:
Based on the behavioral priming literature in psychology, which shows that activating one mental construct increases the tendency of people to engage in mentally related behaviors, one may conjecture that activating “oddness,” may lead people to act in less traditional ways, e.g., seeking information from non-traditional sources. I used data from the GSS and examined if respondents who were randomly assigned an odd respondent ID (1,3,5…) were more likely to report reading horoscopes.
The first column in the table below shows this implausible hypothesis was supported by the data, p<.01 (STATA code) [5]
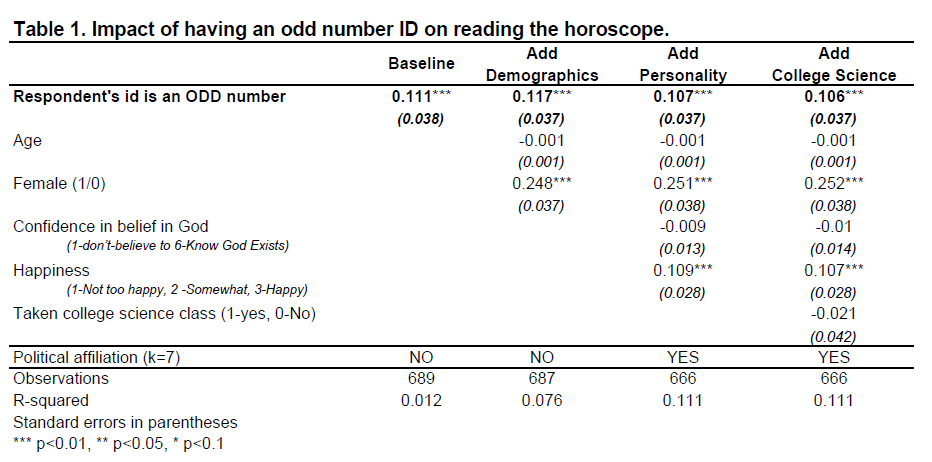 People are about 11 percentage points more likely to read the horoscope when they are randomly assigned an odd number by the GSS. Moreover, this estimate barely changes across alternative specifications that include more and more covariates, despite the notable increase in R2.
People are about 11 percentage points more likely to read the horoscope when they are randomly assigned an odd number by the GSS. Moreover, this estimate barely changes across alternative specifications that include more and more covariates, despite the notable increase in R2.
How to deal with p-hacked hypotheses?
Replications are the obvious way to tease apart true from false positives. Direct replications, testing the same prediction in new studies, are often not feasible with observational data. In experimental psychology it is common to instead run conceptual replications, examining new hypotheses based on the same underlying theory. We should do more of this in non-experimental work. One big advantage is that with rich data sets we can often run conceptual replications on the same data.
To do a conceptual replication, we start from the theory behind the hypothesis, say "odd numbers prompt use of less traditional sources of information" and test new hypotheses. For example, this theory may predict that odd numbered respondents are more likely to read blogs instead of academic articles, read nutritional labels from foreign countries, or watch niche TV shows [6].
Conceptual replications should be statistically independent from original (under the null).[7] That is to say, if an effect we observe is false-positive, the probability that the conceptual replication obtains p<.05 should be 5%. An example that would violate this would be testing if respondents with odd numbers are more likely to consult tarot readers. If by chance many superstitious individuals received an odd number by the GSS, they will both read the horoscope and consult tarot readers more often. Not independent under the null, hence not a good conceptual replication with the same data.
Moderation
A closely related alternative is also commonly used in experimental psychology: moderation. Does the effect get smaller/larger when the theory predicts it should?
For example, I once examined how the price of infant carseats sold on eBay responded to a new safety rating by Consumer Reports (CR), and to its retraction (surprisingly, the retraction was completely effective, .pdf). A referee noted that if the effects were indeed caused by CR information, they should be stronger for new carseats, as CR advises against buying used ones. If I had a false-positive in my hands we would not expect moderation to work (it did).
Summary
1. With field data it’s easy to p-hack hypotheses.
2. The resulting false-positive findings will be robust to alternative specifications
3. Tools common in experimental psychology, conceptual replications and testing moderation, are viable solutions.
![]()
Footnotes.
- As with most forms of p-hacking, selectively reporting hypotheses typically does not involve willful deception. [↩]
- I chose weather and spelling bee as an arbitrary example. Any resemblance to actual papers is seriously unintentional. [↩]
- (1-.95^6)=.2649 [↩]
- Robustness tests may help with the selective reporting of hypothesis if a spurious finding is obtained due to specification rather than sampling error. [↩]
- This finding is necessarily false-positive because ID numbers are assigned after the opportunity to read the horoscope has passed, and respondents are unaware of the number they have been assigned to; but see Bem (2011 .htm) [↩]
- This opens the door to more selective reporting as a researcher may attempt many conceptual replications and report only the one(s) that worked. By virtue of using the same dataset to test a fixed theory, however, this is relatively easy to catch/correct if reviewers and readers have access to the set of variables available to the researcher and hence can at least partially identify the menu of conceptual replications available. [↩]
- Red font clarification added after tweet from Sanjay Srivastava .htm [↩]