Consider these paraphrased famous findings:
“Because his name resembles ‘dentist,’ Dennis became one” (JPSP, .pdf)
“Because the applicant was black (named Jamal instead of Greg) he was not interviewed” (AER, .pdf)
“Because the applicant was female (named Jennifer instead of John), she got a lower offer” (PNAS, .pdf)
Everything that matters (income, age, location, religion) correlates with people’s names, hence comparing people with different names involves comparing people with potentially different everything that matters.
This post highlights the problem and proposes three practical solutions. [1]
Gender
Jennifer was the #1 baby girl name between 1970 & 1984, while John has been a top-30 boy name for the last 120 years. Comparing reactions to profiles with these names pits mental associations about women in their late 30s/early 40s with those of men of unclear age.
More generally, close your eyes and think of Jennifers. Now do that for Johns.
Is gender the only difference between the two sets of people you considered?
Here is what Google did when I asked it to close its eyes: [2]
| Jennifer |  |
| John |  |
Johns vary more in age, appearance, affluence, and presidential ambitions. For somewhat harder data, I consulted a website where people rate names on various attributes: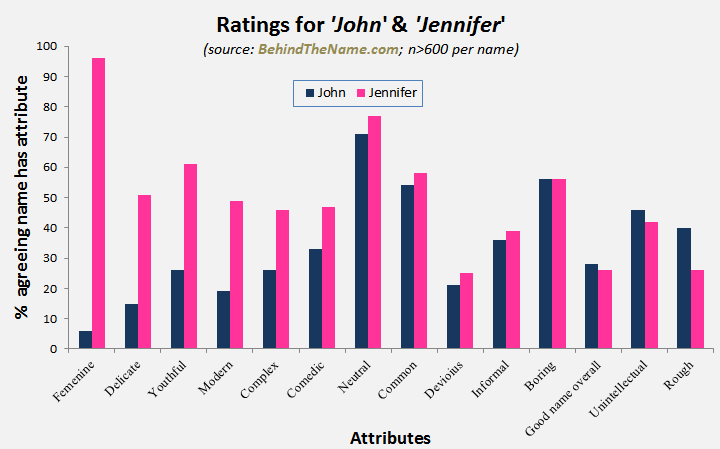
Race
Distinctively black names (e.g., Jamal and Lakisha) signal low socioeconomic status while typical White names do not (QJE .pdf). Do people not want to hire Jamal because he is Black or because he is of low status?
Even if all distinctively Black names (and even Black people) were perceived as low status, and hence Jamal were an externally valid signal of Blackness, the contrast with Greg might nevertheless be low in internal validity, because the difference attributed to race could instead be the result of status (or some other confounding variable). This is addressable because some (most?) low status people are not Black. We could compare Black names vs. low-status White names: say Jamal with Bubba or Billy Bob, and Lakisha with Bambi or Billy Jean. This would allow assessing racial discrimination above and beyond status discrimination. [3]  Imagine reading a movie script where a Black drug dealer is being defended by a brilliant Black lawyer. One of these characters is named Greg, the other Jamal. The intuition that Greg is the lawyer’s name, is the intuition behind the internal validity problem.
Imagine reading a movie script where a Black drug dealer is being defended by a brilliant Black lawyer. One of these characters is named Greg, the other Jamal. The intuition that Greg is the lawyer’s name, is the intuition behind the internal validity problem.
Solution 1. Stop using names
Probably the best solution is to stop using names to manipulate race and gender. A recent paper (PNAS .pdf) examined gender discrimination using only pronouns (and found that academics in STEM fields favored females over males 2:1).
Solution 2. Choose many names
A great paper titled “Stimulus Sampling” (PSPB .pdf) argues convincingly for choosing many stimuli for any given manipulation to avoid stumbling on unforeseen confounds. Stimulus sampling would involve going beyond Jennifer vs. John, to using, say, 20 female vs. 20 male names. This helps with idiosyncratic confounds (e.g., age) but not with the systematic confound that most distinctively Black names signal low socioeconomic status. [4]
Solution 3. Choose control names actively
If one chooses to study names, then one needs to select control names that if it weren’t for the scientific hypothesis of interest, would produce no difference with the target names (e.g., if it weren’t for racial discrimination, then people should like Jamal and this other name just as much)
I close with an example from a paper of mine where I attempted to generate proper control names to examine if people disproportionately marry others with similar names, e.g. Eric-Erica, because of implicit egotism: a preference for things that resemble the self. (JPSP .pdf)
We need control names that we would expect to marry Ericas just as frequently as Erics do in the absence of implicit egotism (e.g., of similar age, religion, income, class and location). To find such names I looked at the relative frequency of wife names for every male name and asked “What male names have the most similar distribution of wife names to Erics?” [5].
The answer was: Joseph, Frank and Carl. We would expect these three names to marry Erica just as frequently as Eric does, if not for implicit egotism. And we would be right.
For the Jamal vs. Greg study, we could compare Jamal to non-Black names that have the most similar distribution of occupations, or of Zip Codes, or of criminal records.
![]()
Feedback from original authors:
I shared an early draft of this post with the authors of the Jamal vs. Greg, and Jennifer vs. John study.
Sendhil Mullainathan, co-author of the former, indicated across a few emails he did not believe it was clear one should control for socioeconomic status differences in studies about race, because status and race are correlated in real life.
Corinne Moss-Racusin sent me a note she wrote with her co-authors of their PNAS study:
Thanks so much for contacting us about this interesting topic. We agree that these are thoughtful and important points, and have often grappled with them in our own research. The names we used (John and Jennifer) had been pretested and rated as equivalent on a number of dimensions including warmth, competence, likeability, intelligence, and typicality (Brescoll & Uhlmann, 2005 .pdf), but they were not rated for perceived age, as you highlight here. However, for our study in particular, age of the target should not have extensively impacted our results, because the age of both our targets could easily be inferred from the targets’ resume information that our participants were exposed to. Both the male and female targets (John and Jennifer respectively) were presented as recent college grads (with the same graduation year), and it is thus reasonable to assume that participants believed they were the same age, as recent college grads are almost always the same age (give or take a few years). Thus, although it is possible that age (and other potential variables) may indeed be confounded with gender across our manipulation, we nonetheless do not believe that choosing different male and female names that were equivalent for age would greatly impact our findings, given our design. That said, future research should still seek to replicate our key findings using different manipulations of target gender. Specifically, your suggestions (using only pronouns, and using multiple names) are particularly promising. We have also considered utilizing target pictures in the past, but have encountered issues relating to attractiveness and other confounds.
Footnotes.
- Galen Bodenhausen read this post and told me about a paper on confounds in names used for gender research, from 1993(!) PsychBull .pdf[↩]
- Based on the Jennifers and Johns I see, I suspect Google peeked at my cookies before closing its eyes,e.g., there are two bay area business school professors. Your results may differ. [↩]
- Bertrand and Mullainathan write extensively about the socioeconomic confound and report a few null results that they interpret as suggesting it is not playing a large role (see their Section “V.B Potential Confounds”, .pdf). However, (1) the n.s. results of socioeconomic status are obtained with extremely noisy proxies and small samples, reducing the ability to conclude evidence of absence from the absence of evidence, and on the other, (2) these analyses seek to remedy the consequences of the name-confound rather than avoiding the confound from the get-go through experimental design. This post is about experimental design.[↩]
- The Jamal paper used 9 different names per race/gender cell[↩]
- To avoid biasing the test against implicit egotism, I excluded from the calculations male and female names starting with E_[↩]