An impressive team of researchers is engaging in an impressive task: Replicate 21 social science experiments published in Nature and Science in 2010-2015 (.htm).
The task requires making many difficult decisions, including what sample sizes to use. The authors’ current plan is a simple rule: Set n for the replication so that it would have 90% power to detect an effect that’s 75% as large as the original effect size estimate. If “it fails” (p>.05), try again powering for an effect 50% as big as original.
In this post I examine the statistical properties of this “90-75-50” heuristic, concluding it is probably not the best solution available. It is noisy and wasteful [1].
Noisy n.
It takes a huge sample to precisely estimate effect size (ballpark: n=3000 per cell, see DataColada[20]). Typical experiments, with much smaller ns, provide extremely noisy estimates of effect size; sample size calculations for replications, based on such estimates, are extremely noisy as well.
As a calibration let’s contrast 90-75-50 with the “Small-Telescopes” approach (.htm), which requires replications to have 2.5 times the original sample size to ensure 80% power to accept the null. Zero noise.
The figure below illustrates. It considers an original study that was powered at 50% with a sample size of 50 per cell. What sample size will that original study recommend for the first replication (powered 90% for 75% of observed effect)? The answer is a wide distribution of sample sizes reflecting the wide distribution of effect size estimates the original could result in [2]. Again, this is the recommendation for replicating the exact same study, with the same true effect and same underlying power; the variance you see for the replication recommendation purely reflects sampling error in the original study (R Code). 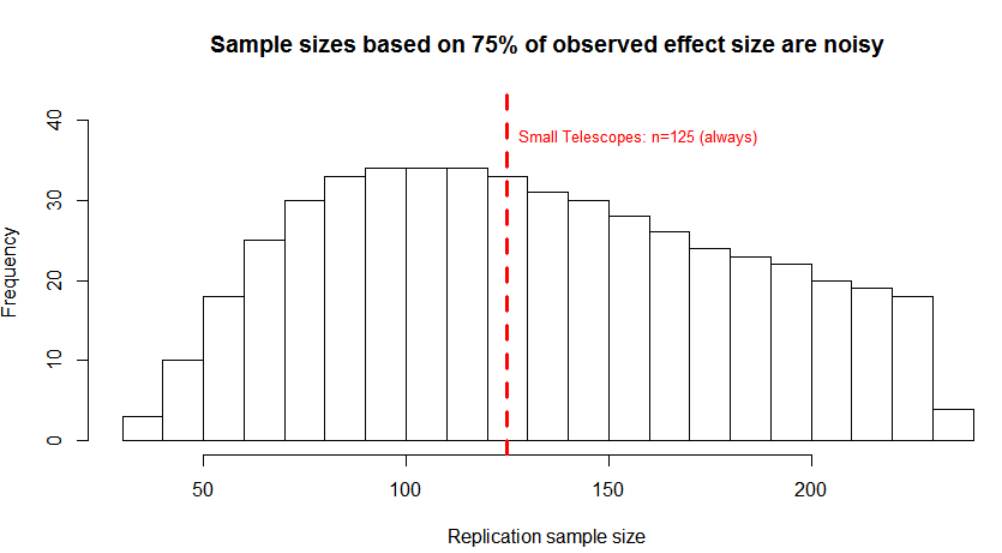
We can think of this figure as the roulette wheel being used to set the replication’s sample size.
The average sample size recommendations of both procedures are similar: n=125 for the Small Telescopes approach vs. n=133 for 90-75-50. But the heuristic has lots of noise: the standard deviation of its recommendations is 50 observations, more than 1/3 of its average recommendation of 133 [3].
Waste
The 90-75-50 heuristic throws good money after bad, escalating commitment to studies that have already accepted the null. Consider an original study that is false-positive with n=20. Given the distribution of (p<.05) possible original effect-size estimates, 90-75-50 will on average recommends n=67 per-cell for the first replication, and when that one fails (which it will with 97.5% chance because the original is false-positive), it will run a second replication now with n=150 participants per-cell (R Code).
From the “Small Telescopes” paper (.htm) we know that if 2.5 times the original (n=20) were run in the first replication, n=50, we already would have an 80% chance to accept the null. So in the vast majority of cases, when replicating it with n=67, we will already have accepted the null; why throw another n=150 at it? That dramatic explosion of sample size for false-positive original findings is about the same for any original n, such that:
False-positive original findings lead to replications with about 12 times as many subjects per-cell when relying on 90-75-50.
If the false-positive original was p-hacked, it’s worse. The original p-value will be close to p=.05, meaning a smaller estimated original effect size and hence even larger replication sample size. For instance, if the false-positive original got p=.049, 90-75-50 will trigger replications with 14 times the original sample size (R Code).
Rejecting the null
So far we have focused on power and wasted observations for accepting the null. What if the null is false? The figure below shows power for rejecting the null. We see that if the original study had even mediocre power, say 40%, the gains of going beyond 2.5 times the original are modest. The Small Telescopes approach provides reasonable power to accept and also to reject the null (R Code).

Better solution.
Given the purpose (and budget) of this replication effort, the Small-Telescopes recommendation could be increased to 3.5n instead of 2.5n, giving nearly 90% power to accept the null [4].
The Small Telescopes approach requires fewer participants overall than 90-75-50 does, is unaffected by statistical noise, and it paves the way to a much needed “Do we accept the null?” mindset to interpreting ‘failed’ replications.
![]()
Author feedback.
Our policy is to contact authors whose work we discuss, asking to suggest changes and reply within our blog if they wish. I shared a draft with several of the authors behind the Social Science Replication Project and discussed it with a few them. They helped me clarify the depiction of their sample-size selection heuristic, prompted me to drop a discussion I had involving biased power estimates for the replications, and prompted me -indirectly- to add the entire calculations and discussions involving waste that’s included in the post you just read. Their response was prompt and valuable.
- The data-peeking involved in the 2nd replication inflates false-positives a bit, from 5% to about 7%, but since replications involve directional predictions, if they use two-sided tests, it’s fine.[↩]
- The calculations behind the figure work as follows. One begins with the true effect size, the one giving the original sample 50% power. Then one computes how likely each possible significant effect size estimate is, that is, the distribution of possible effect size estimates for the original (this comes straight from the non-central distribution). Then one computes for each effect size estimate, the sample size recommendation for the replication that the 90-75-50 heuristic would result in, that is, one based on an effect 75% as big as the estimate, and since we know how likely each estimate is, we know how likely each recommendation is, and that’s what’s plotted.[↩]
- How noisy the 90-75-50 heuristic recommendation is depends primarily on the power of the original study and not the specific sample and effect sizes behind such power. If the original study has 50% power, the SD of the recommendation over the average recommendation is ~37% (e.g., 50/133) whether the original had n=50, n=200 or n=500. If underlying power is 80%, the ratio is ~46% for those same three sample sizes. See Section (5) in the R Code[↩]
- Could also do the test half-way, after 1.75n, ending study if already conclusive; using a slightly stricter p-value cutoff to maintain desired false-positive rates; hi there @lakens[↩]