As you may know, Harvard professor Francesca Gino is suing us for defamation after (1) we alerted Harvard to evidence of fraud in four studies that she co-authored, (2) Harvard investigated and placed her on administrative leave, and (3) we summarized the evidence in four blog posts.
As part of their investigation, Harvard wrote a 1,288-page report describing what they found. Because of the lawsuit, that report was made public: .pdf. And because it was made public, we now know what the investigators say was in the "original" dataset for one of the four studies: Study 3A of Gino, Kouchaki, and Casciaro (2020) [1]. By simply comparing the Original and Posted versions of the dataset, we can see exactly how the data were altered to produce the published result. In this post, we will show that:
- We correctly deduced how the data were altered.
- Gino's prevailing explanation for the alterations is extremely implausible.
Gino, Kouchaki, & Casciaro (2020, Study 3A)
This study was summarized in Colada 112 (.htm) in a post titled “Forgetting The Words”. Briefly, 599 participants were randomly assigned to one of three conditions:
- Promotion condition: wrote about their hopes and aspirations.
- Prevention condition: wrote about their duties and obligations.
- Control condition: wrote about what they did yesterday.
They then read about a networking event and rated how dirty, tainted, inauthentic, ashamed, wrong, unnatural, and impure they felt about it. These seven items were averaged to form a measure of “moral impurity”.
They then described their feelings about the networking event in a few words.
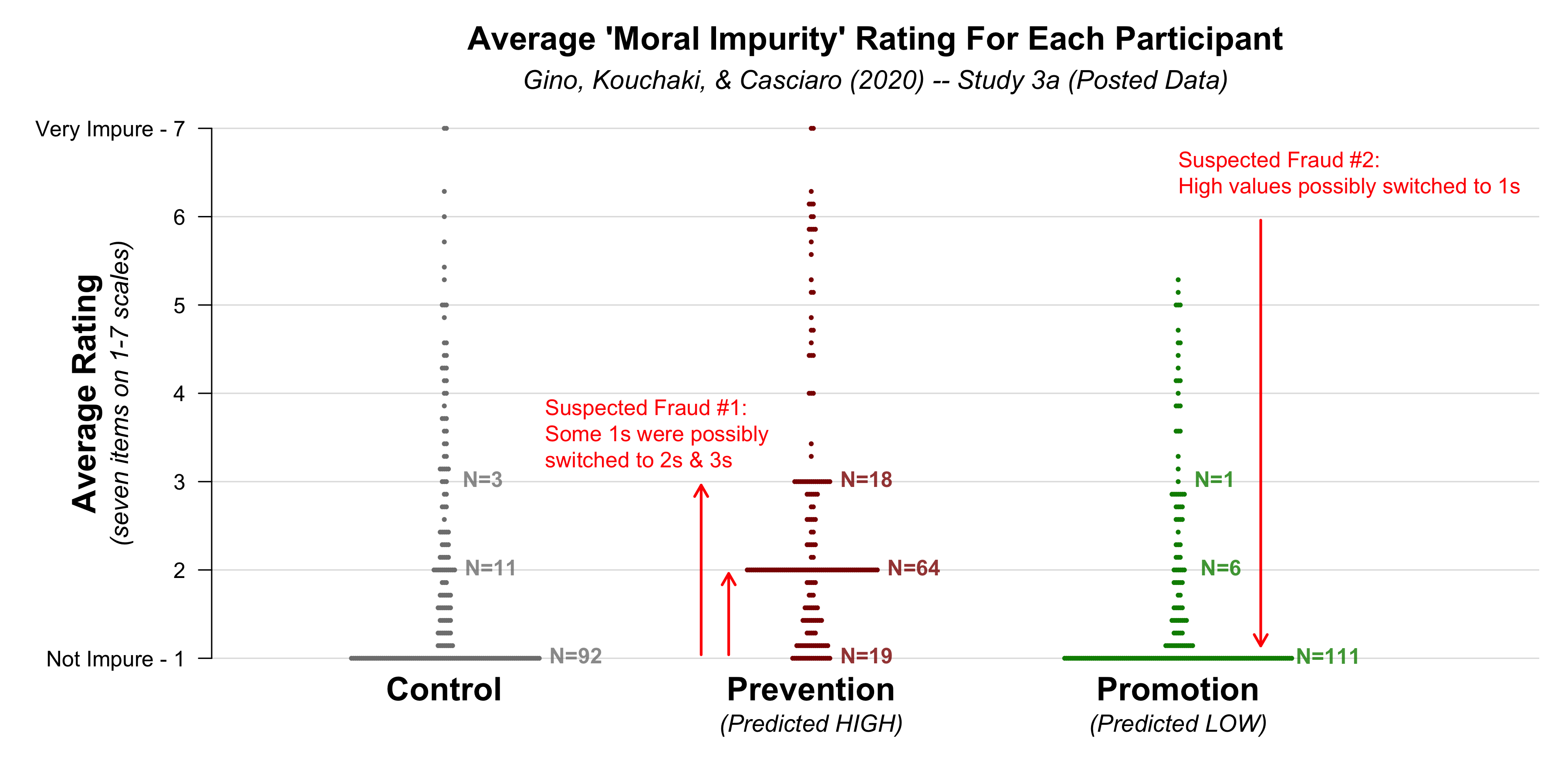
The authors hypothesized and reported that ratings of moral impurity were highest in the Prevention condition and lowest in the Promotion condition. However, this effect exists only in the Posted data, not in the Original data, suggesting that the data were altered to produce the desired result.
Reconstructing The Original Data Set
Pages 517-520 of the Harvard report allow us to reconstruct what was in the Original dataset for this study [2].
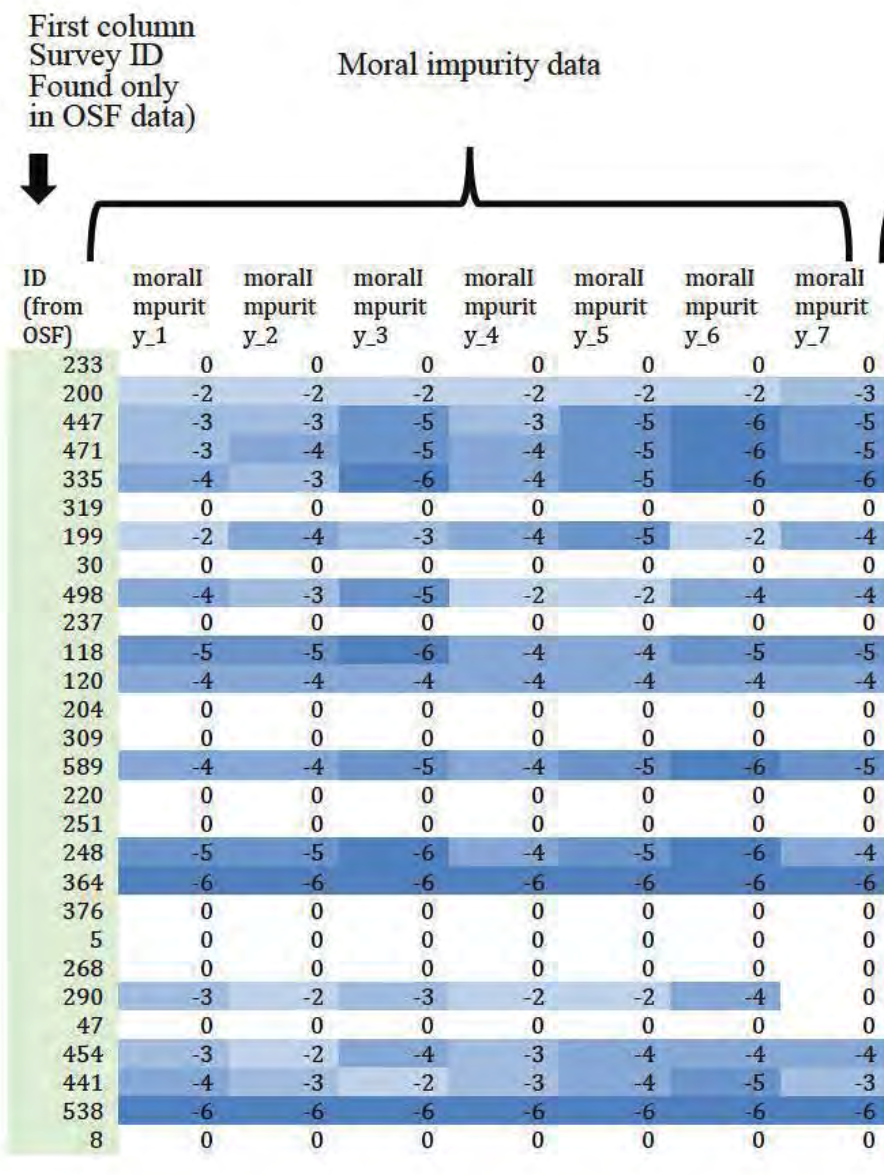
Here’s an annotated screenshot taken from page 517 [3]. This screenshot shows data from the Promotion condition, predicted to have lower feelings of moral impurity:
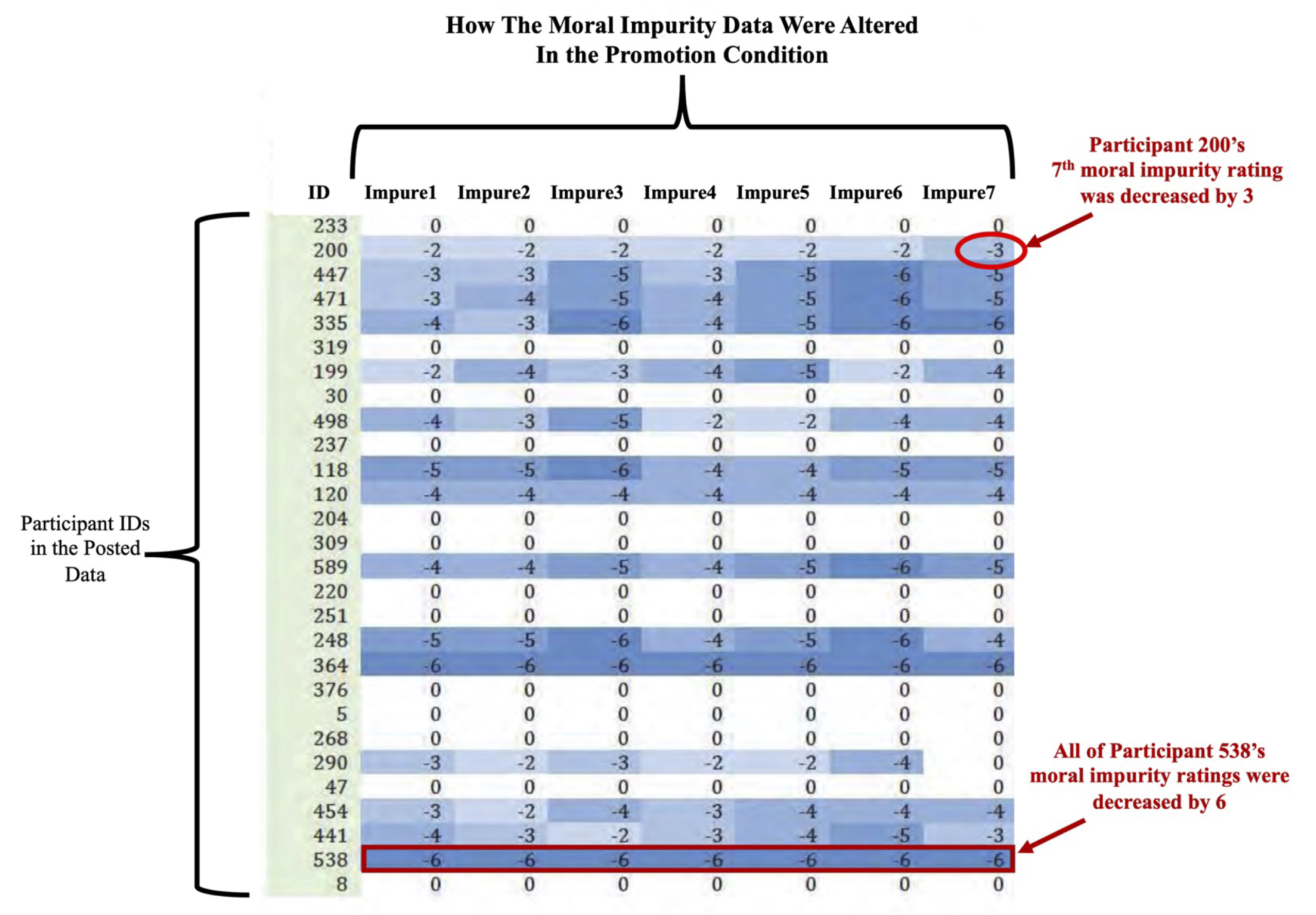
In the gray column on the far left you can see a list of the ID numbers that were in the Posted/Altered dataset [4]. Then, in the next seven columns, the ones that contain a lot of blue highlighting, you see the seven moral impurity items and exactly how Harvard's investigators say they were changed from the Original file to the Posted file [5].
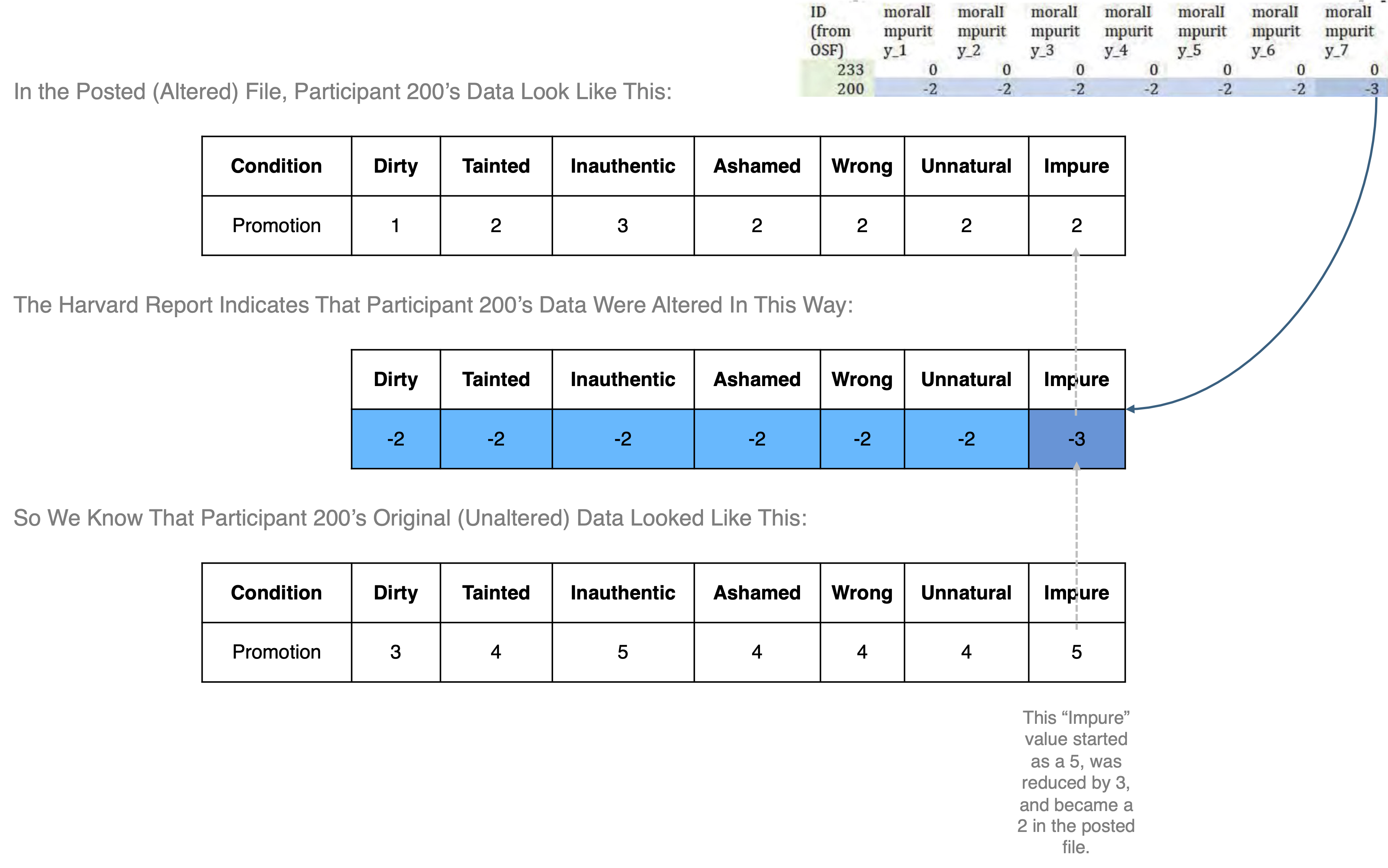
So, for example, in the second row you can see that Participant 200’s seven moral impurity ratings were decreased by 2, 2, 2, 2, 2, 2, 3. In the Posted/Altered data file Participant 200 had ratings of 1, 2, 3, 2, 2, 3, 1, and so we know that her original ratings were 3, 4, 5, 4, 4, 5, 4:
Starting on page 517, the report shows all 104(!) altered rows of moral impurity values, as well as exactly how they were altered [6].
How Were The Data Altered?
As a reminder, the authors wanted the moral impurity ratings to be high in the Prevention condition and low in the Promotion condition.
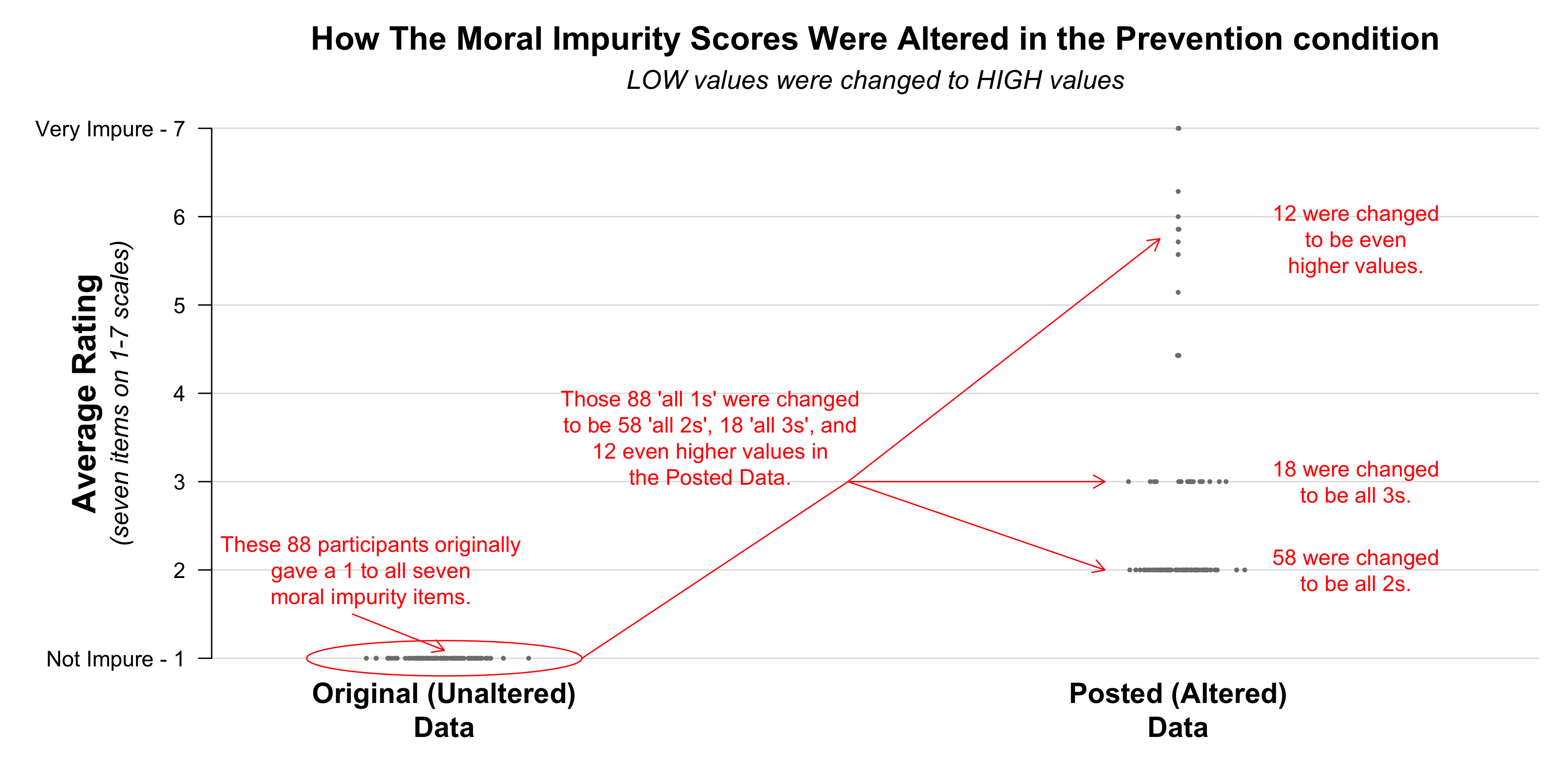
And that is what they said they found. This figure, which appeared in Data Colada 112 and in our report to Harvard [7], shows every moral impurity score in the Posted dataset, while also summarizing our suspicions about how the data were altered.
As you can see, we had suspected two types of fraud.
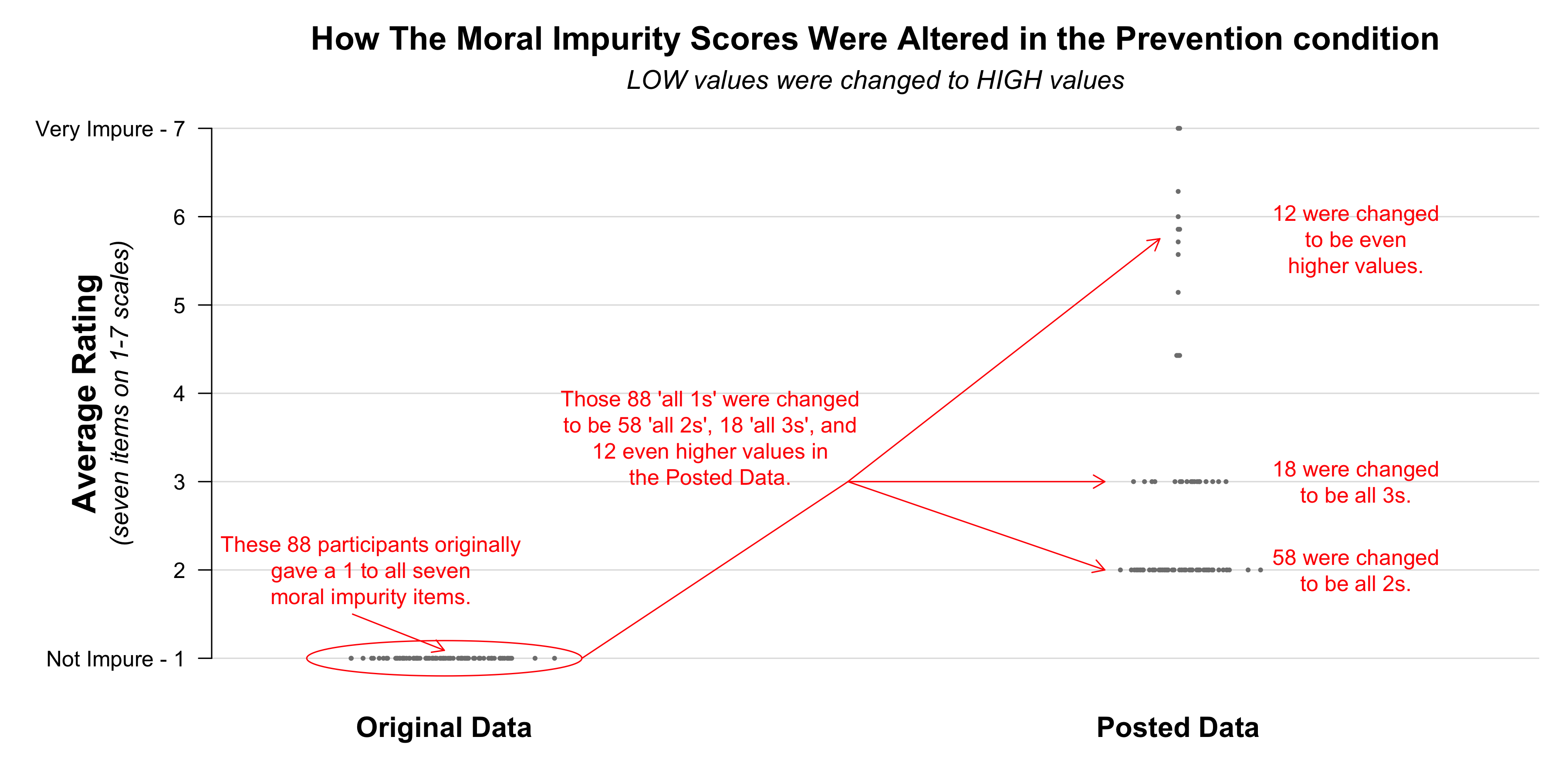
First, in the Prevention condition, it looked like there were too few participants who gave “all 1s” to all seven moral impurity items, and too many participants who gave “all 2s” and “all 3s”. This led us to suspect that many of the “all 1s” were changed to “all 2s” and “all 3s” in order to produce the hypothesized result.
Now that we can see what was in the Original dataset, we know that 88 moral impurity ratings were changed within the Prevention condition. The figure below shows how they were changed. As you can see, we were right. The moral impurity scores of 58 participants were changed from being all 1s to all 2s, while all 18 of the “all 3s” in the Posted data file had originally been “all 1s”. There were an additional 12 observations that were changed to be even higher values.
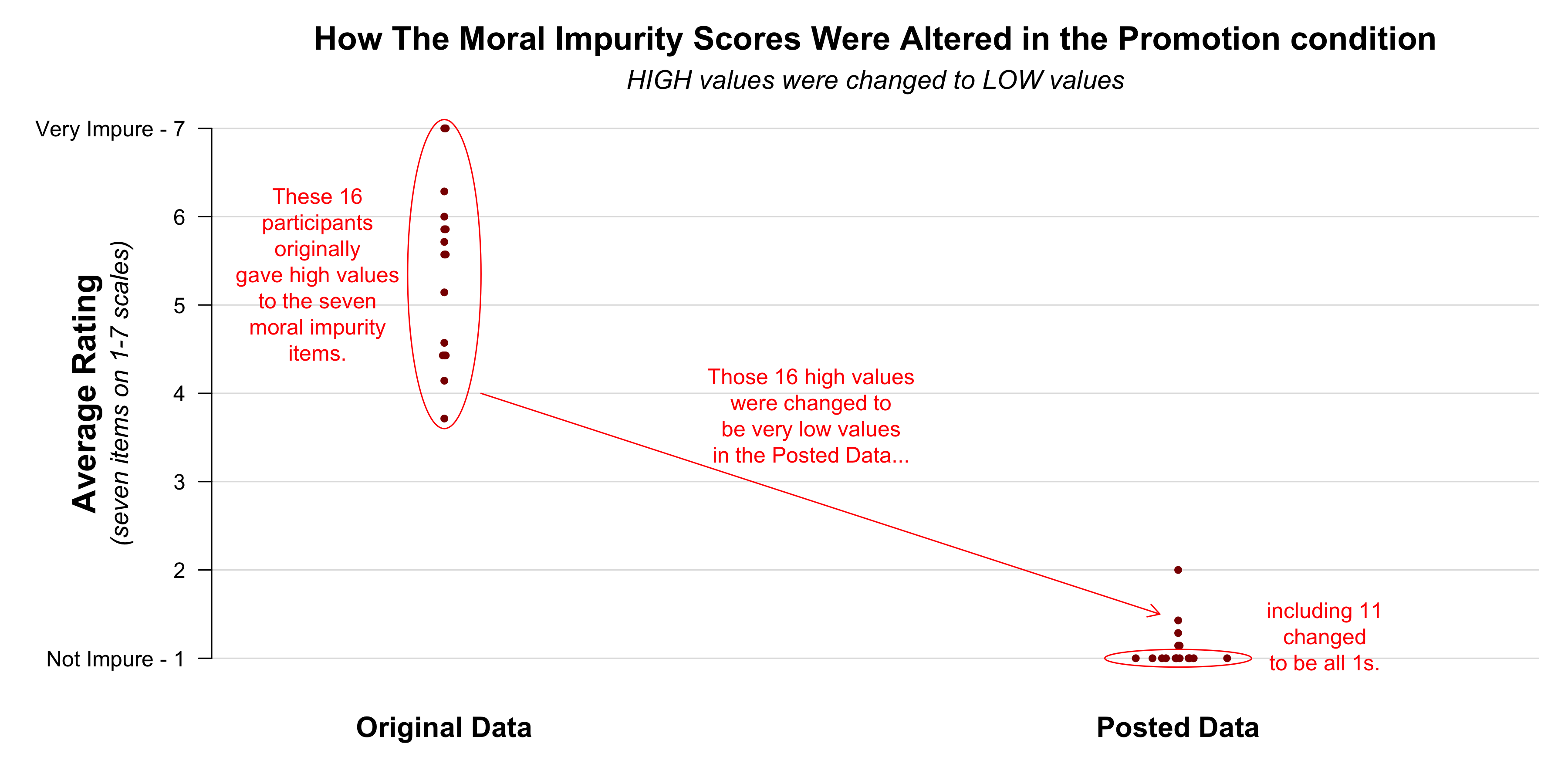
Second, in the Promotion condition it looked like there were too many participants who gave “all 1s” and too few participants who gave very high values to the moral impurity items. This led us to suspect that some very high ratings had been changed to all 1s.
And, indeed, as summarized below, the Harvard investigation found that that is exactly what happened. In the Promotion condition, 16 observations were changed. ALL of them were high values that were changed to be very low values:
So our hypothesis of how the data were altered has been confirmed.
Does Gino's Prevailing Explanation Make Sense?
Gino and her legal team have tried to explain these discrepancies by suggesting that the Posted file contains the real data and what the Harvard investigators call the Original data – the data on the survey platform – were somehow altered [8], [9].
What would have to be true for this to be true?
- A “bad actor” accessed Gino’s password-protected Qualtrics account and altered values, and somehow without ever leaving a trace.
- That actor changed the data so that the results were no longer supportive of the original hypothesis. That is, the study’s reported findings are true, and the null effect observed in the “Original” data is a fabrication.
- The anomalies described in the previous section were present in the real data but not in the fake data.
And if these three implications aren’t implausible enough, her explanation also implies a fourth:
- The real data were nonsensical, and a bad actor changed them to make them make sense.
Let’s walk through it.
In our initial investigation, we found that many of the suspicious observations had a peculiar feature: the ratings that participants gave did not match the words they wrote.
For example, consider Participant 538, who was in the Promotion condition. In the Posted dataset, this participant’s ratings indicated that they didn’t feel “dirty” at all. But they literally wrote that the event made them feel “dirty”.

We thought that participants like this originally had high ratings that were changed to be low. And, indeed, the Harvard Report confirmed that that’s true. Participant 538’s “all 7s” had been changed to “all 1s”:
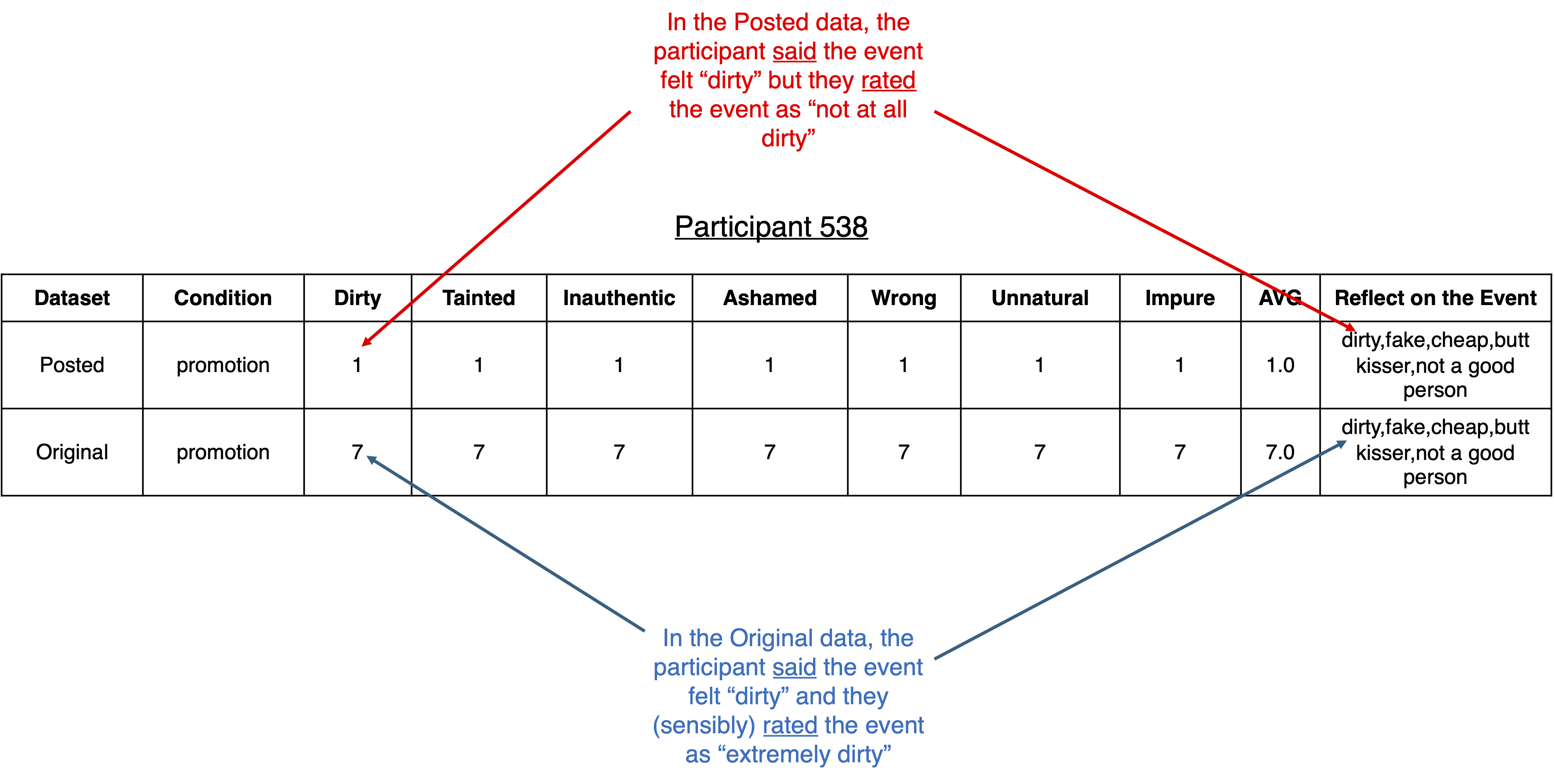
But Gino’s conjecture implies that we are wrong: It’s not that the 1s are supposed to be 7s, it’s that the 7s are supposed to be 1s! By her account, the participant who wrote “dirty” truly rated the event to be “not at all dirty”. Only when someone broke into her account and changed that rating to "extremely dirty" did the rating come to align with the participant's words. In other words, her claim requires us to believe that Participant 538’s data were originally nonsensical, but that some bad actor changed them to make sense.
This is not the only example. For instance, here is a participant in the Prevention condition whose moral impurity ratings were changed from “all 1s” to higher numbers:
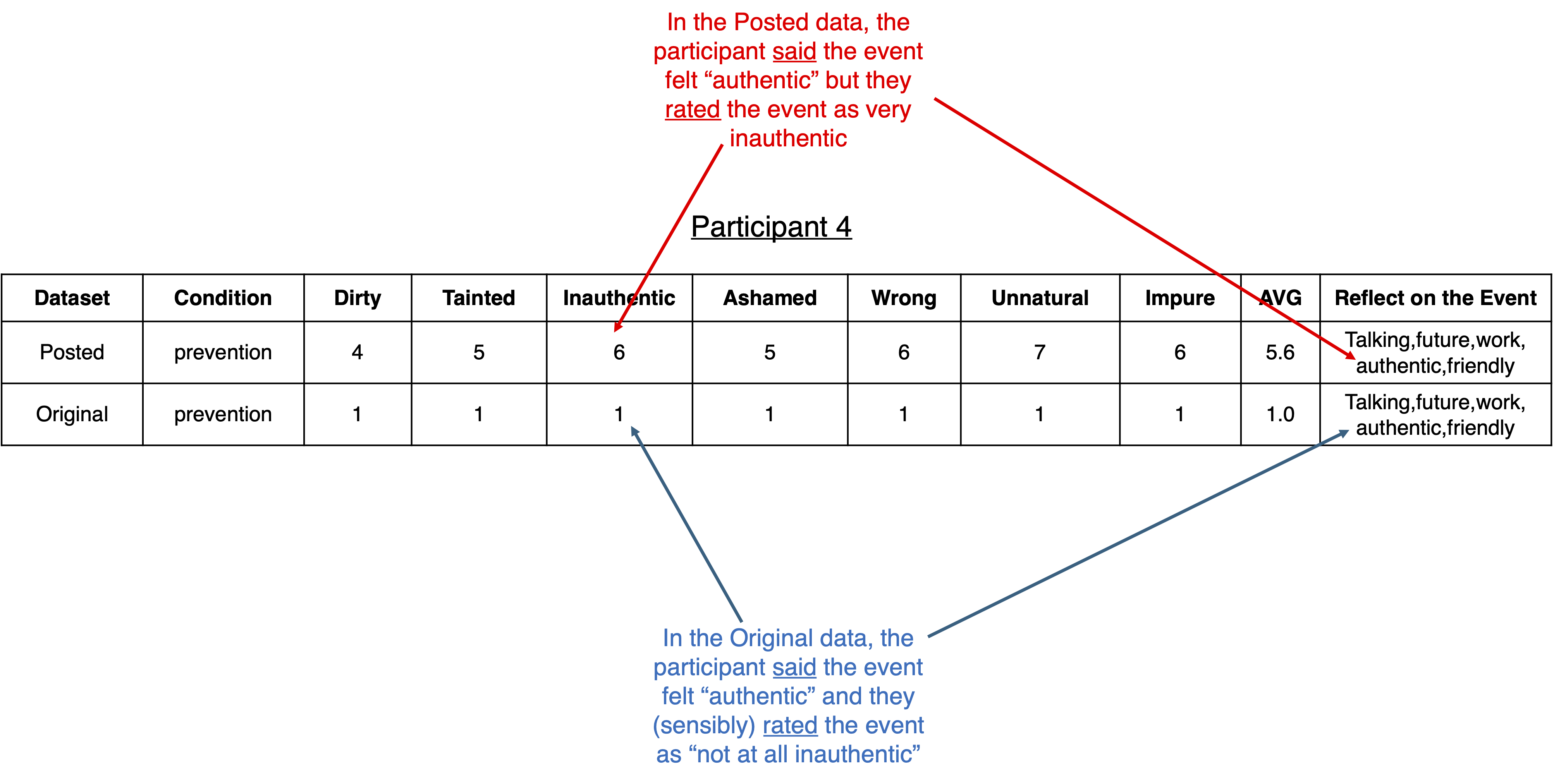
Gino’s hypothesis says that Participant 4 said that the event was “authentic” but truly rated the event as “inauthentic”. Our hypothesis, confirmed by Harvard, says that Participant 4 said that the event was “authentic” and truly rated the event as “authentic”.
We can look at this more completely. We had asked some workers to rate the positivity/negativity of the words that participants wrote about the networking event. This allows us to see the relationship between those word ratings and the moral impurity ratings. If these word ratings are valid, then participants who gave higher ratings of moral impurity should have written words that were rated to be more negative. And, indeed, in the Original dataset, this is what you see:
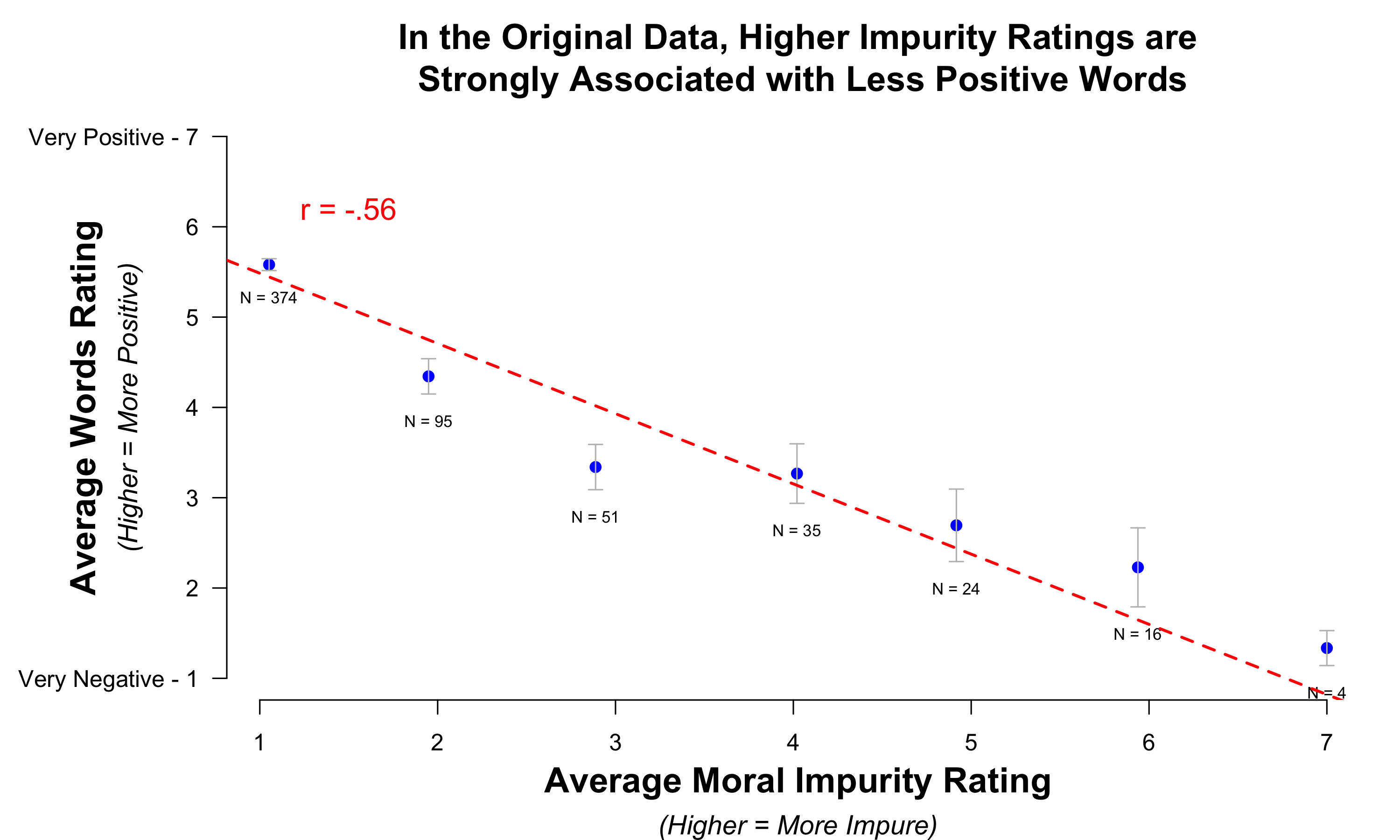
When people gave negative ratings they said negative things. When people gave positive ratings they said positive things. Of course [10].
Now if Gino’s hypothesis were true – if the Posted data are real and the Original data were altered – then we should see a more sensible relationship between the words and the ratings within the Posted dataset than within the Original dataset. We can test this by looking at the words/ratings relationship in the 104 altered observations. Is that relationship more sensible in the Posted data than in the Original data?:
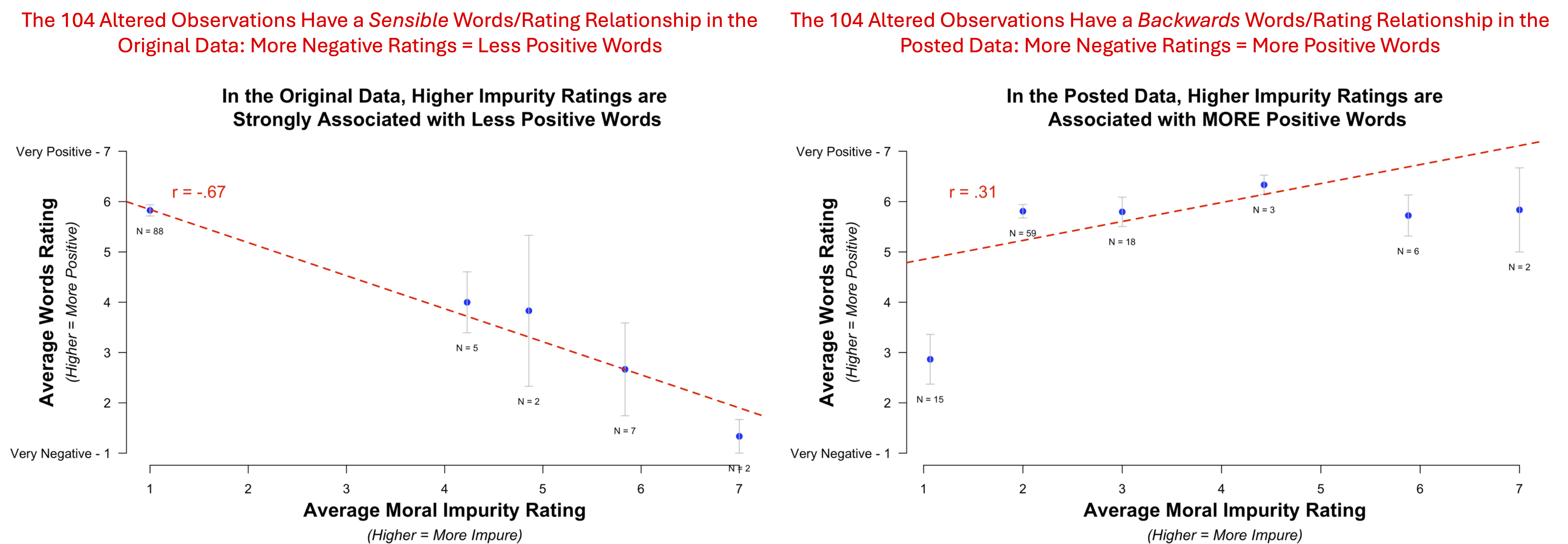
No. Opposite. In the Original data, the relationship is completely sensible: more negative ratings = less positive words. In the Posted data, it is . . . backwards: more negative ratings = more positive words.
To believe that the Original data are fake and the Posted data are real, you’d have to believe that the sensible data are fake and the backwards data are real. That is a difficult thing to believe.
An easier thing to believe is that when the fraudster changed the ratings, she forgot to change the words, and so, when she altered them, the relationship between the words and the ratings got all cattywampus [11].
Conclusions
We were right about how the data were altered, Gino’s prevailing explanation for the alterations does not make sense, and yet we are the defendants in this case.
![]()
Footnotes.
- The report contains analyses conducted by an independent data forensic firm that Harvard hired to analyze Gino’s data. For Study 3A of Gino, Kouchaki, and Casciaro (2020) the firm compared the Posted data file that served as the basis of the published result to the “Original” data file obtained directly from Gino’s Qualtrics account. The forensic firm’s report reads: “According to the client [Harvard], the Qualtrics files’ location was provided by the respondent [Gino] and identified as the original/raw data file utilized for the 2020 JPSP Paper” (p. 512). We will refer to this data file as the “Original” file throughout this blog post. [↩]
- All data and code for this post, including what is needed to re-construct the Original dataset, can be found here: https://researchbox.org/3124. [↩]
- We altered the screenshot to make it easier to digest. Here's a picture of the actual screenshot: .png. [↩]
- The Original file did not have ID numbers but because participants wrote essays and words, it was easy to match the Original data to the Posted data (see page 515 of the Harvard Report). For example, in the Posted file Promotion-condition Participant 200 wrote, “This is a bit hard for me because I have a lot of hope and aspirations (maybe not much confidence which is what I'm working on). I really want to be an entrepreneur (online business, writing, and songwriting) and work for myself. Also I would love to travel the world and visit at least five different countries that I've never been to and be a missionary to help those in need. Being a successful entrepreneur could help me achieve traveling and helping others less fortunate.” All you have to do is locate the participant in the Original file who wrote this exact thing, and then you know that you’ve found Participant 200. [↩]
- Readers may wonder why some of the above rows contain all zeroes, implying that nothing was altered. Actually, the table in the report contains four additional columns, which show that (and how) participants’ responses to four additional “networking intentions” items were also altered, and also in the direction of the authors’ hypothesis. Rows with all zeroes in the screenshot above are actually rows in which “only” the networking intentions items were altered (and not the moral impurity items). Since these networking intentions items were not the focus of our original concerns, we don’t discuss them here. But this is simply us choosing simplicity over thoroughness. Pages 517-525 of the Harvard Report show that they were altered too. [↩]
- Actually, the report shows *168* rows of altered observations. 104 featured changes to the moral impurity items. The remaining “only” featured changes to the networking intentions items. See previous footnote. [↩]
- The figure was slightly but not meaningfully different in our report to Harvard. [↩]
- For example, the Harvard Report says, “[Gino] speculated that an actor with malicious intentions to ‘hurt’ her, an actor with whom she may have shared her login information in the past, may have altered the … data directly in her Qualtrics account, after the paper was published and the dataset posted on OSF” (p. 19). In her response to Harvard’s inquiry, Gino wrote, “It is also possible that the dataset posted on OSF does reflect the original data and the Qualtrics data set instead does not, as someone with access to my Qualtrics account may have modified it. Thus, tampering by a motivated third party cannot and should not be ruled out” (Harvard Report, p. 1043-1044). She reiterated this in her legal complaint (.pdf): “The data in Qualtrics was *not* the original data for Study 3a, as it was verifiably edited” (p. 47, emphasis in original), as well as, “Harvard never proved . . . that the dataset posted on OSF by Professor Gino does not reflect the original data” (p. 59). And in the motion-to-dismiss hearing in Boston on April 26th, Gino’s lawyer said, “All of the retraction notices contain statements that the data sets that Professor Gino posted on the Open [Science Framework] were not the ‘original data sets’ used for the study at issue. All of the retraction notices said that the ‘original data’ had been altered. These are all false statements of fact.” Thus, Gino and her legal team have clearly put forward the notion that what Harvard has called the “original” data are not in fact the original data. [↩]
- In her response to Harvard Gino also suggested that perhaps “an RA who cleaned the data made an honest error in the process” (p. 1043) and that “any errors would have certainly been unintentional” (p. 1044) and “there is no evidence to suggest that such errors are intentional” (p. 1044). But the facts that (1) there were 168 alterations and (2) those alterations so strongly benefitted the authors’ hypothesis seem hard to square with an “innocent-errors” account. [↩]
- The mere existence of this obvious relationship definitively rebuts one of Gino’s accusations against us in the lawsuit. Her complaint reads, “Data Colada . . . *knew* that coding the ‘words’ they had their coders rate for positivity or negativity not only had nothing to do with the hypothesis that was being tested in Professor Gino’s study, but further, would [be] such a subjective exercise as to be useless” (p. 59, our emphasis). We take this to mean that we *knew* that (1) that raters could not reliably decide whether words like “dirty” or “authentic” were positive or negative, a claim that is obviously false, and (2) there is no relationship between the words participants wrote and the ratings that they gave, a claim that both defies common sense and is definitively contradicted by these data. It is bizarre to be accused of *knowing* both of these (obviously false) things. It is like being accused of *knowing* that the sky is orange. [↩]
- Definition: “something that is in disarray, that is askew, or something that isn’t directly across from something”; .htm. [↩]
{kind=link}