This post introduces ResearchBox, a new platform for easily sharing data, code, materials, and pre-registrations. With a design and approach similar to AsPredicted, ResearchBox simplifies, standardizes, and organizes supporting materials for publishable research.
Compared to the current leading platform, the OSF, ResearchBox is narrowly designed to make it easy for authors to share data, code, materials and pre-registrations with their readers. It is not designed to also serve as a research collaboration tool, and so does not offer features such as project forking, subcomponents associated with different authors, wiki contributions, or AWS integration.
We hope and believe that ResearchBox's narrower aims make it an irresistibly easy-to-use platform that will further encourage researchers, and consumers of research, to engage in and benefit from the use of open research practices.
In this post, we will first discuss the benefits of open research. Then we will discuss how ResearchBox makes it easy to do open research.
If you are an impatient reader, you can open a new tab to look at our 30+ favorite ResearchBox features (with some arguably pretty pictures). If you are a patient reader, you will see this link offered again.

BENEFITS OF OPEN RESEARCH
Benefit 1: Error Detection
Because researchers are human, the research we publish contains errors. To correct these errors, our peers need to find them. While some errors are findable from information included in the paper itself, many are not. Miscoded variables, programming errors, inaccurate descriptions of the methods, confounds embedded in the original materials, mistakes made when copying output, and incorrectly applied R functions, are all errors that can invalidate a paper's conclusions while being invisible to those who read the published article.
Benefit 2: Reducing Fraud
As researchers we work very hard. In return we get some prestige, flexible working hours, the opportunity to hang out with smart and interesting people, and eventually job security. These unusual rewards, however, invite parasites: people who can't make an honest living in science, but want to live as if they could. Fabricateurs steal the jobs, publications, newspaper headlines, grant money, and editorial positions from our hardworking peers. It is relatively easy to fake data when all you have to report is a table of results. It is harder (and scarier) when you have to report materials, code, and data. Almost all (of the many, many) cases of fraud we know involve detection via original data, code, or materials. When most honest researchers make their research open, most research parasites will look for a new host.
Benefit 3: Preserving Our Own Understanding Of Our Work
To make our research open, we must organize and permanently archive the needed files while they still make sense to us as authors. This curation enables us to return to our files years after publishing a paper, and still know what is what. Making our research open preserves our own understanding of our work at its peak.
Benefit 4: Learning From Our Peers
Imagine you want to learn how to run mixed-design ANOVAs in R. Wouldn’t it be nice to get the code for a paper you know, written by a researcher you admire, that uses that exact analysis? Wouldn’t it be nice to have taken a PhD methods class in which students learn each tool by looking at the code and data from published research? Yes, it would. We could learn a lot from seeing what our peers and mentors have done.
Benefit 5: Helping Methods Research Be More Relevant
If methodologists could easily observe real life data and analyses, they could more easily identify what their fields need. Imagine if a mediation expert could easily download all data used to conduct mediation analyses in JPSP papers published in 2019. Wouldn’t that researcher be better equipped to make a contribution to how psychologists run mediation analyses? And wouldn't those same JPSP authors benefit from reading a methods paper that is relevant to how they go about their daily mediation business? Expecting methodologists to develop useful insights without sharing our data and code with them is like expecting doctors to make us feel better without telling them what our symptoms are.
RESEARCHBOX
We created ResearchBox with three main goals. We wanted to (1) simplify, (2) standardize, and (3) organize open research. We made every ResearchBox design decision with those goals in minds.
Authors store all files from the same project in a Box. That Box should be both:
- Easy for authors to create.
- Easy for readers to make sense of.
Standardization & organization provides this desired simplicity. All boxes display available files in a "Bingo Table" like this: [1]
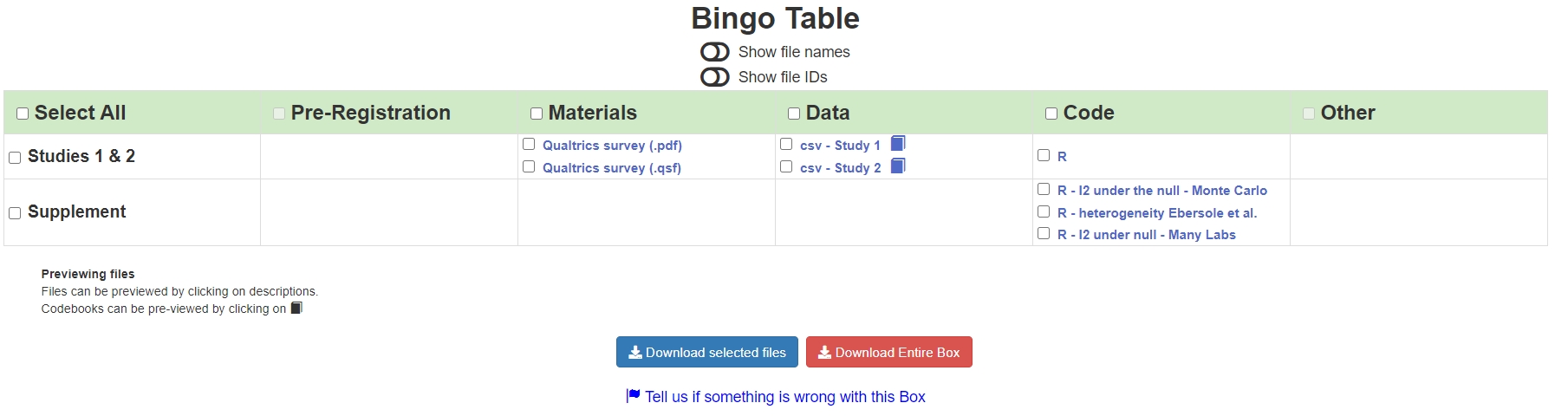
All Bingo Tables have the same 5 columns.
The rows vary from box to box, with section names determined by the authors.
Bingo Tables immediately reveal what is and, importantly, what is not available. For example, in the box above you can easily see that only Studies 3 & 4 were pre-registered. Bingo tables also immediately reveal what each file is relevant for.
Apart from the Bingo table structure, our 3 favorite ResearchBox features are that all datasets have codebooks (!!), files have quick previews (including datasets of any size), and readers can download all files in a box with one click (see red button in image above). Click here to see our favorite 30+ features.
ResearchBox's robot is named Dolores.
While AsPredicted is integrated with ResearchBox, Larry will stick to the former.
HOW TO USE RESEARCHBOX
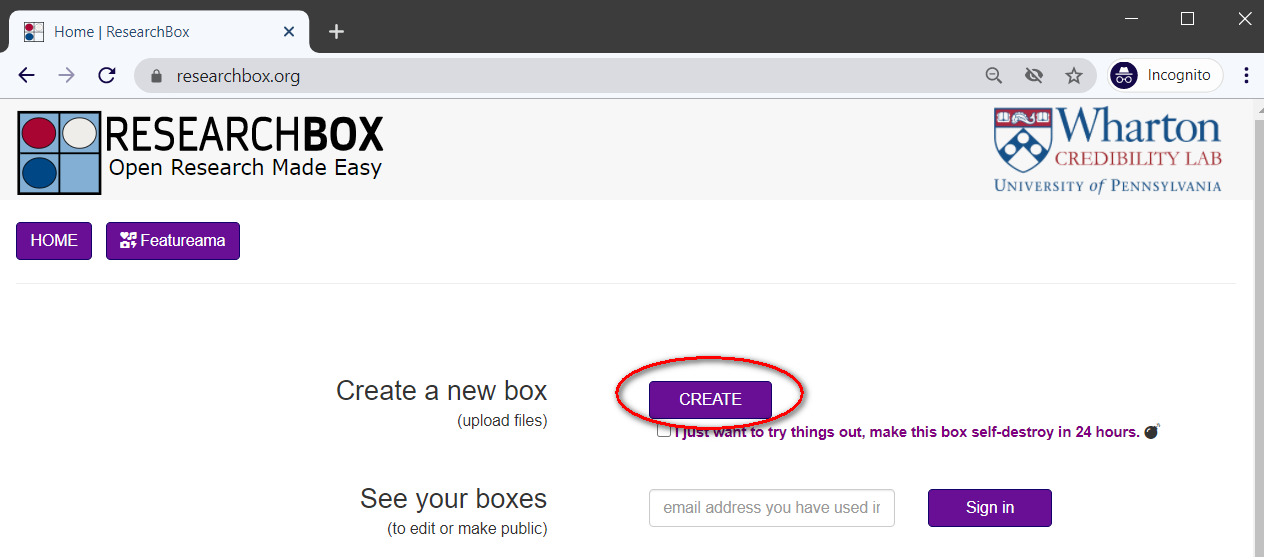
1. Go to researchbox.org (which like AsPredicted, does not require passwords).
2. Click CREATE.
3. Drop the files you wish to upload into the middle blue box.
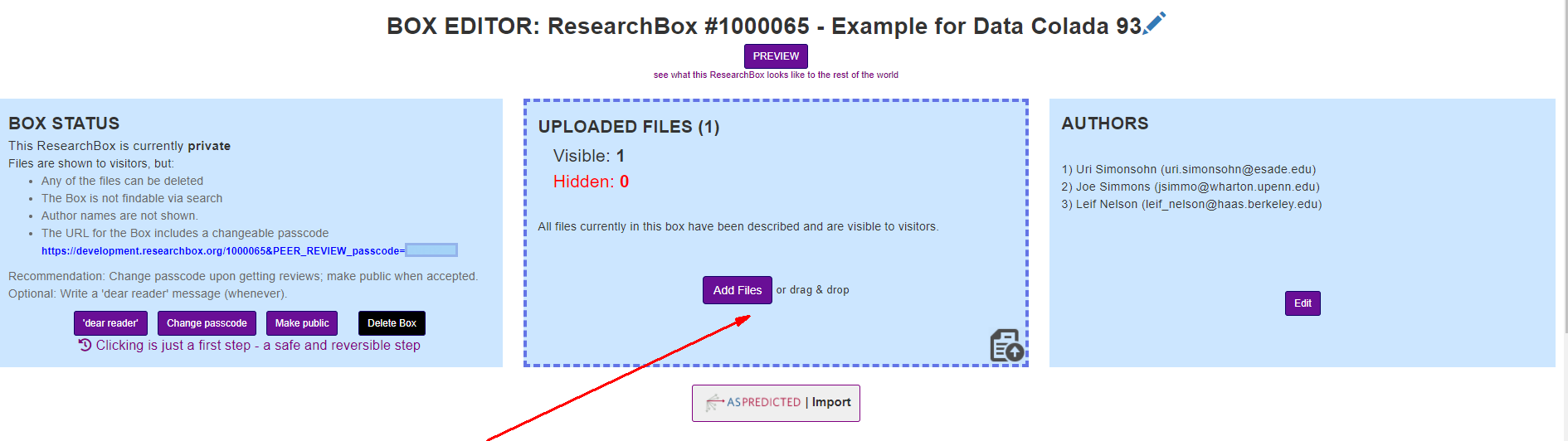
4. Click the 'pending' buttons to provide the information needed to place the file within the Bingo Table.
![]()
5. All boxes are private by default, meaning (1) author names are not shown, (2) files can be added and deleted, and (3) the link to the anonymized box includes a changeable passcode. Once the research is published, authors make their boxes public, at which point the box becomes non-anonymous and permanent, and its link is simply the box number, like this: https://researchbox.org/15 or https://researchbox.org/17.
ResearchBox is funded by the Wharton School at the University of Pennsylvania, and run by the Wharton Credibility Lab. We hope you like it.
![]()
Footnotes.
- Why bingo? The table visually resembles bingo cards, and when you look for something on ResearchBox you will be loudly thinking "bingo!" shortly after starting that search. The table structure has no purposeful connection to the farmer's dog who name-o was Bing-o. [↩]