It is now common for researchers to post original materials, data, and/or code behind their published research. That’s obviously great, but open research is often difficult to find and understand.
In this post I discuss 8 things I do, in my papers, code, and datafiles, to combat that.
Paper
1) Before all method sections, I include a paragraph overviewing the open research practices behind the paper. Like this:

2) Just before the end the paper, I put the supplement’s table of contents. And the text reads something like “An online supplement is available, Table 1 summarizes its contents”

3) In tables and figure captions, I include links to code that reproduces them

#Code
4) I start my code indicating authorship, last update, and contact info.
5) I then provide an outline of its structure
Like this:
Then, through the code i use those same numbers so people can navigate the code easily [1].
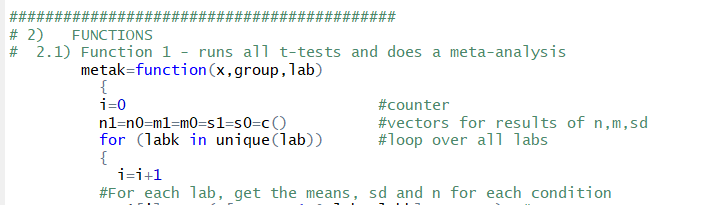
6) Rule-of-thumb: At least one comment per every 3 lines of code.
Even if something is easy to figure out, a comment will make reading code more efficient and less aversive. But most things are not so easy to figure out. Moreover, nobody understands your code as well as you do when you are writing it, including yourself 72 hours later.
When writing comments in code, it is useful to keep in mind who may actually read it, see footnote for longer discussion [2].
Data
7) Codebook (very important). Best to have a simple stand-alone text file that looks like this, variable name followed by description that includes info on possible values and relevant collection details.

8) Post the rawest form of data that I am able/allowed to. All data cleaning is then done in code that is posted as well. When cleaning is extensive, I post both raw and cleaned datafiles
Note: writing this post helped me realize I don’t always do all 8 in every paper. I will try to going forward.
In sum.
1. In paper: open-research statement
2. In paper: supplement’s table of contents
3. In figure captions: links to reproducible code
4. In code: contact info and description
5. In code: outline of program below
6. In code: At least one comment per every three lines
7. Data: post codebook (text file, variable name, description)
8. Data: post (also) rawest version of data possible
![]()
Footnotes.
- I think this comes from learning BASIC as a kid (my first programming language), where all code went in numbered lines like
10 PRINT “Hola Uri”
20 GOTO 10.[↩] - Let’s think about who will be reading your code.
One type of reader is someone learning how to use the programming language or statistical technique you used, help that person out and spell things out for them. Wouldn’t you have liked that when you were learning? So if you use a non-vanilla procedure, throw your reader a bone and explain in 10 words stuff they could learn if they read the 3 page help file they shouldn’t really be expected to read just to follow what you did. Throw in references and links to further reading when pertinent but make your code as self-contained as possible.Another type of reader is at least as sophisticated as you are, but does things differently from you, so cannot quite understand what you are doing (e.g., you parallel loops, they vectorize). If they don’t quite understand what you did, they will be less likely to learn from your code, or help you identify errors in it. What’s the point of posting it then? This is especially true in R, where there are 20 ways to do everything, and some really trivial stuff is a pain to do.
Another type of reader lives in the future, say 5 years from today, when the approach, library, structure or even programming language you use is not used any more. Help that person map what you did into the language/function/program of the future. Also, that person will one day be you.
The cost of excessive commenting is a few minutes of your time typing text people may not read just to be thorough and prevent errors. That’s what we do most of our time anyway.[↩]