Pre-registering a study consists of leaving a written record of how it will be conducted and analyzed. Very few researchers currently pre-register their studies. Maybe it’s because pre-registering is annoying. Maybe it's because researchers don't want to tie their own hands. Or maybe it's because researchers see no benefit to pre-registering. This post addresses these three possible causes. First, we introduce AsPredicted.org, a new website that makes pre-registration as simple as possible. We then show that pre-registrations don't actually tie researchers' hands, they tie reviewers' hands, providing selfish benefits to authors who pre-register. [1]
AsPredicted.org
The best introduction is arguably the home-page itself: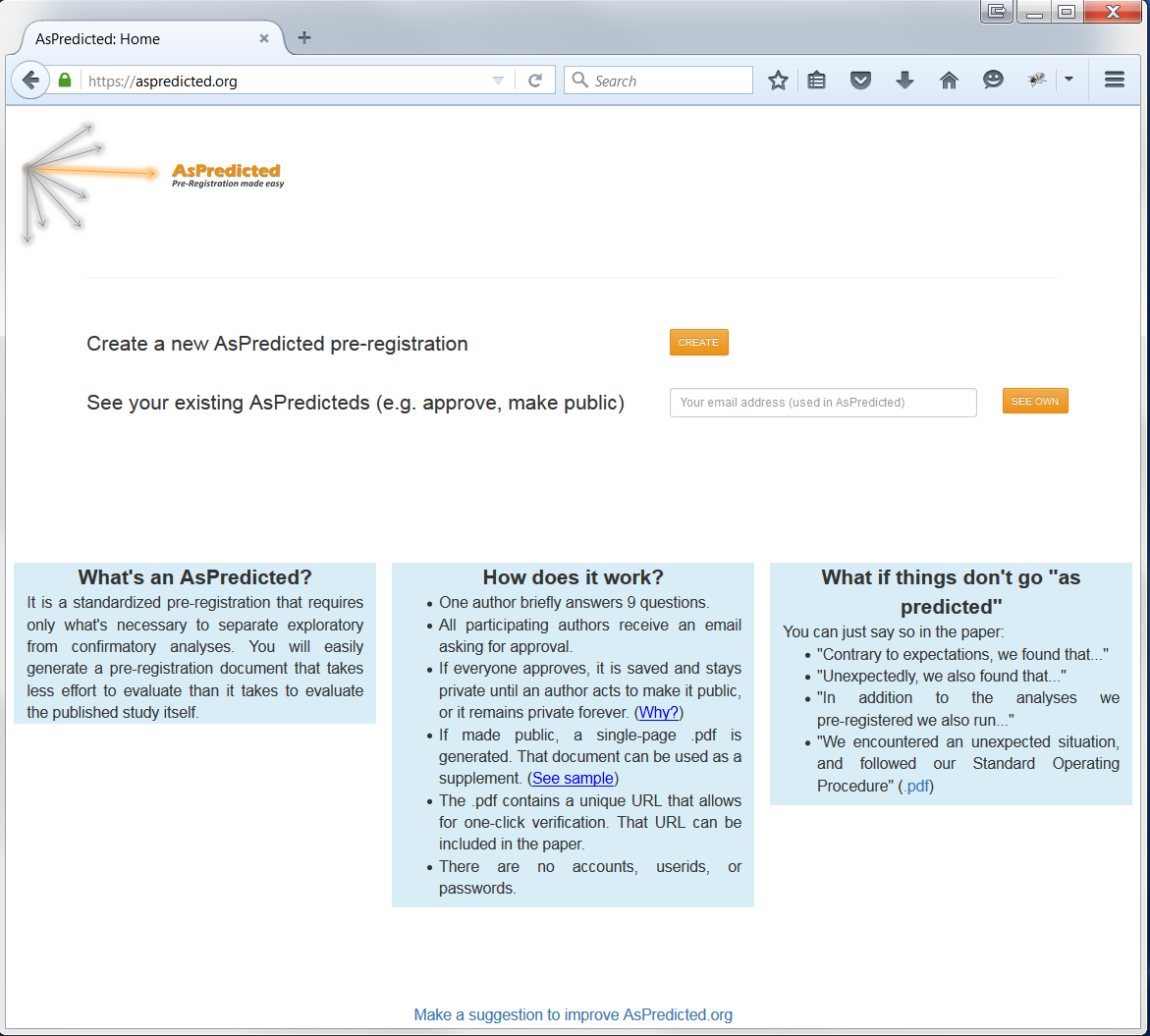
No matter how easy pre-registering becomes, not pre-registering is always easier. What benefits outweigh the small cost?
Benefit 1. No more self-censoring
In part by choice, and in part because some journals (and reviewers) now require it, more and more researchers are writing papers that properly disclose how their studies were run; they are disclosing all experimental conditions, all measures collected, any data exclusions, etc.
Disclosure is good. It appropriately increases one's skepticism of post-hoc analytic decisions. But it also increases one's skepticism of totally reasonable ex-ante decisions, for the two are sometimes confused. Imagine you collect and properly disclose that you measured one primary dependent variable and two exploratory variables, only to get hammered by Reviewer 2, who writes:
This study is obviously p-hacked. The authors collected three measures and only used one as a dependent variable. Reject.
When authors worry that they will be accused of reporting only the best of three measures, they may decide to only collect a single measure. Preregistration frees authors to collect all three, while assuaging any concerns of being accused of p-hacking.
You don’t tie your hands with pre-registration. You tie Reviewer 2’s.
In case you skipped the third blue box above:

Benefit 2. Go ahead, data peek
Data peeking, where one decides whether to get more data after analyzing the data, is usually a big no-no. It invalidates p-values and (several aspects of) Bayesian inference. [2] But if researchers pre-register how they will data peek, it becomes kosher again.
For example, you can pre-register, “In line with Frick (1986; .html) we will check data after every 20 observations per-cell, stopping whenever p<.01 or p>.36,” or “In line with Pocock (1977; .html), we will collect up to 60 observations per-cell, in batches of 20, and stop early if p<.022.”
Lakens (2014; .html) gives an accessible introduction to legalized data-peeking for psychologists.
Benefit 3. Bolster credibility of odd analyses
Sometimes, the best way to analyze the data is difficult to sell to readers. Maybe you want to do a negative binomial regression, or do an arcsine transformation, or drop half the sample because the observations are not independent. You think about it for hours, ask your stat-savvy friends, and then decide that the weird way to analyze your data is actually the right way to analyze your data. Reporting the weird (but correct!) analysis opens you up to accusations of p-hacking. But not if you pre-register it. “We will analyze the data with an arc-sine transformation.” Done. Reviewer 2 can't call you a p-hacker.
![]()
Footnotes.
- More flexible options for pre-registration are offered by the Open Science Framework and the Social Science Registry, where authors can write up documents in any format, covering any aspect of their design or analysis, and without any character limits. See pre-registration instructions for the OSF here , and for the Social Science Registry here. [↩]
- In particular, if authors peek at their data seeking a given Bayes Factor, they increase the odds they will find support for the alternative hypothesis even if the null is true – see Colada [13] – and they obtain biased estimates of effect size. [↩]