Not everything at Data Colada is as serious as fraudulent data. This post is way less serious than that. This post is about music and teaching.
As part of their final exam, my students analyze a data set. For a few years that data set has been a collection of my personal listening data from iTunes over the previous year. The data set has about 500 rows, with each reporting a song from that year, when I purchased it, how many times I listened to it, and a handful of other pieces of information. The students predict the songs I will include on my end-of-year “Leif’s Favorite Songs” compact disc. (Note to the youth: compact discs were physical objects that look a lot like Blu-Ray discs. We used to put them in machines to hear music.) So the students are meant to combine regressions and intuitions to make predictions. I grade them based on how many songs they correctly predict. I love this assignment.
The downside, as my TA tells me, is that my answer key is terrible. The problem is that I am encumbered both by my (slightly) superior statistical sense and my (substantially) superior sense of my own intentions and preferences. You see, a lot goes into the construction of a good mix tape (Note to the youth: tapes were like CD’s, except if you wanted to hear track 1 and then track 8 you were SOL.) I expected my students to account for that. “Ah look,” I am picturing, “he listened a lot to Pumped Up Kicks. But that would be an embarrassing pick. On the other hand, he skipped this Gil Scott-Heron remix a lot, but you know that’s going on there.” They don’t do that. They pick the songs I listen to a lot.
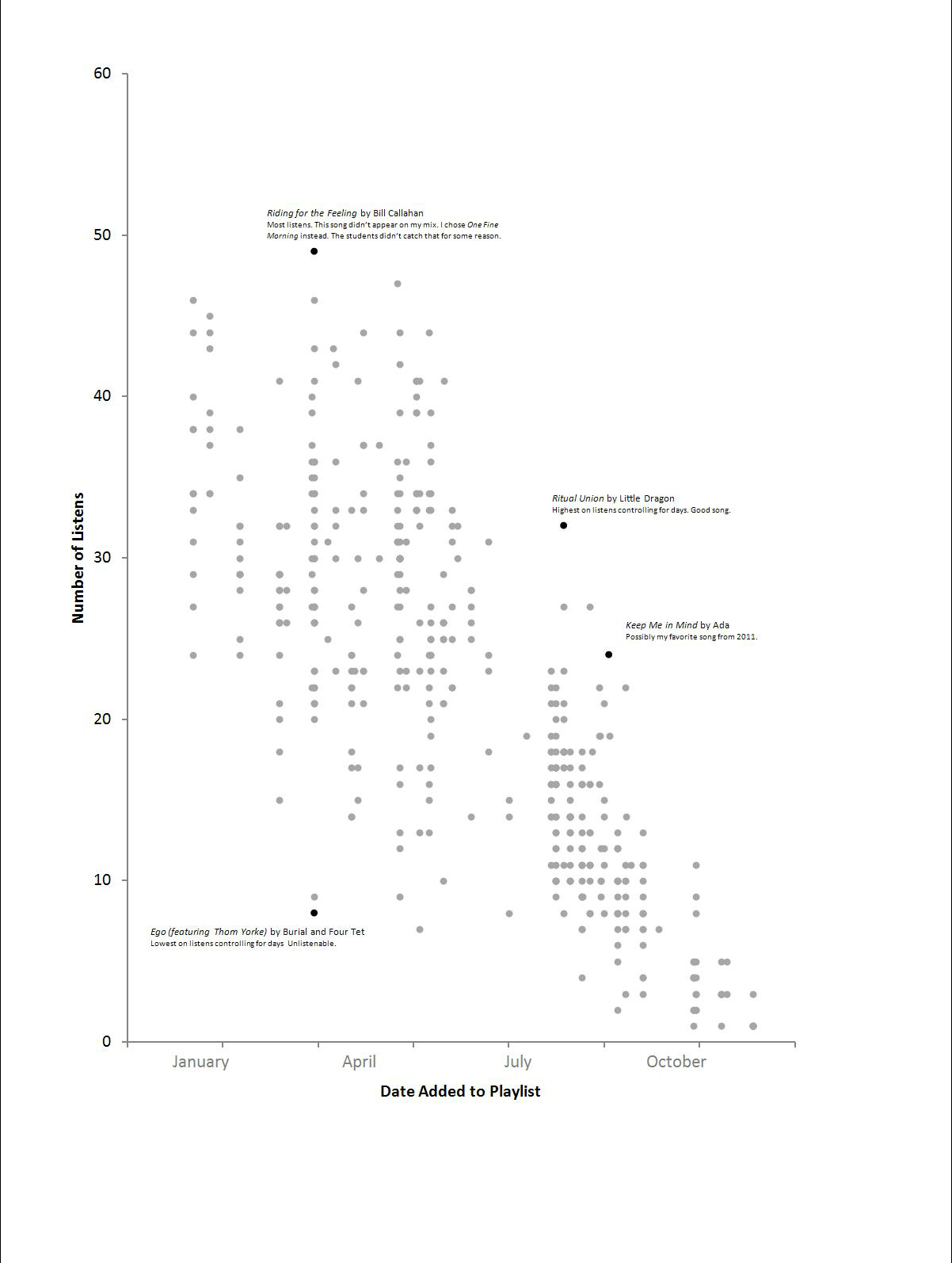
But then they miss certain statistical realities. When it comes to grading, the single biggest differentiator is whether or not a student accounts for how long a song is in the playlist (see the scatterplot of 2011, below). If you don’t account for it, then you think that all of my favorite songs were released in the first couple of months. A solid 50% of students think that I have a mad crush on January music. The other half try to account for it. Some calculate a “listens per day” metric, while others use a standardization procedure of one type or another. I personally use a method that essentially accounts for the likelihood that a song will come up, and therefore heavily discounts the very early tracks and weighs the later tracks all about the same. You may ask, “wait, why are you analyzing your own data?” No good explanation. I will say though, I almost certainly change my preferences based on these analyses – I change them away from what my algorithm predicts. That is bad for the assignment. I am not a perfect teacher.
I don’t think that I will use this assignment anymore since I no longer listen to iTunes. Now I use Spotify. (Note to the old: Spotify is like a musical science fiction miracle that you will never understand. I don’t.)