[19] Fake Data: Mendel vs. Stapel - Data Colada
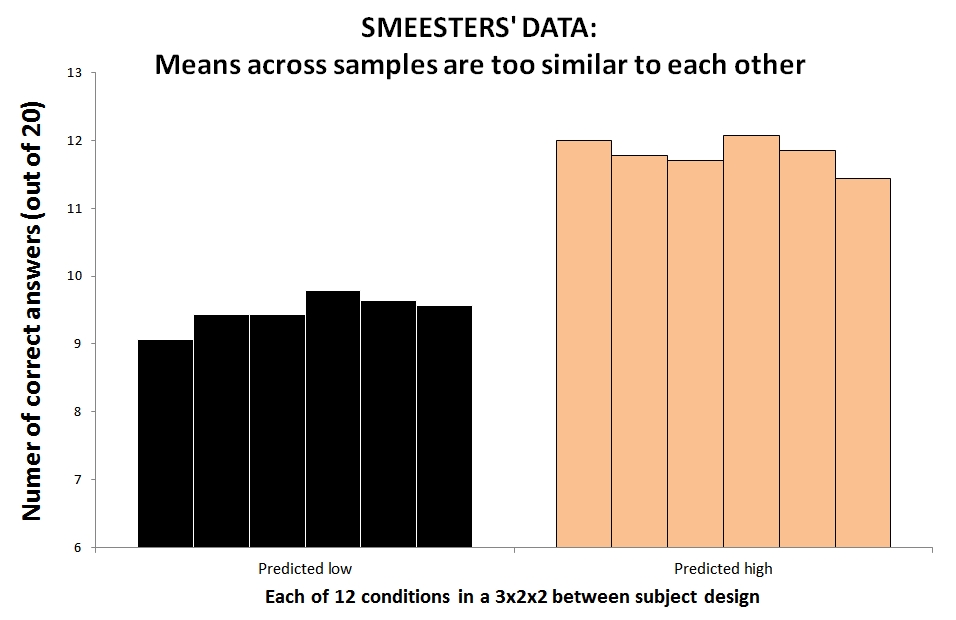
Diederik Stapel, Dirk Smeesters, and Lawrence Sanna published psychology papers with fake data. They each faked in their own idiosyncratic way, nevertheless, their data do share something in common. Real data are noisy. Theirs aren't. Gregor Mendel's data also lack noise (yes, famous peas-experimenter Mendel). Moreover, in a mathematical sense, his data are just as...
Uri Simonsohn